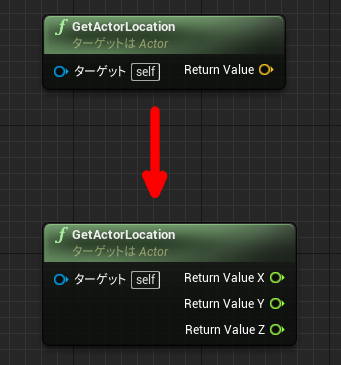
前回の続きです。
・UE4 プログラミング言語 Blueprint (1)
・UE4 プログラミング言語 Blueprint (2)
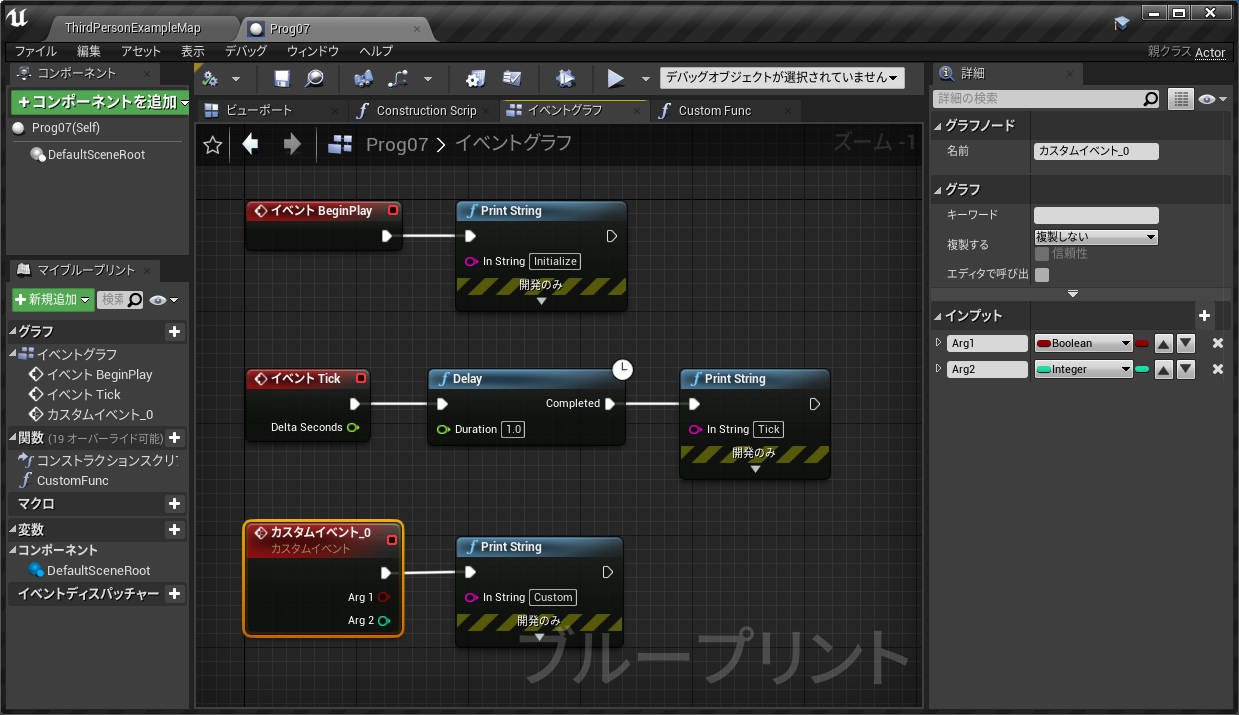
●未実行命令の戻り値
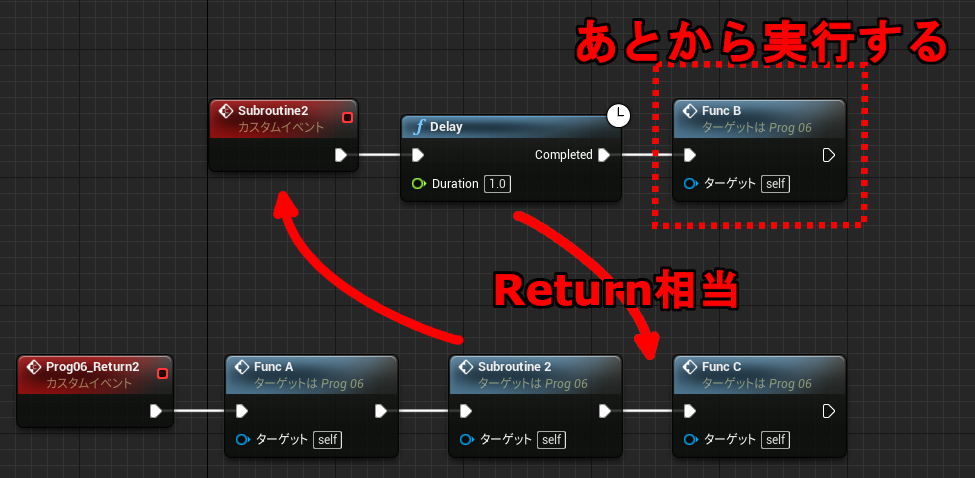
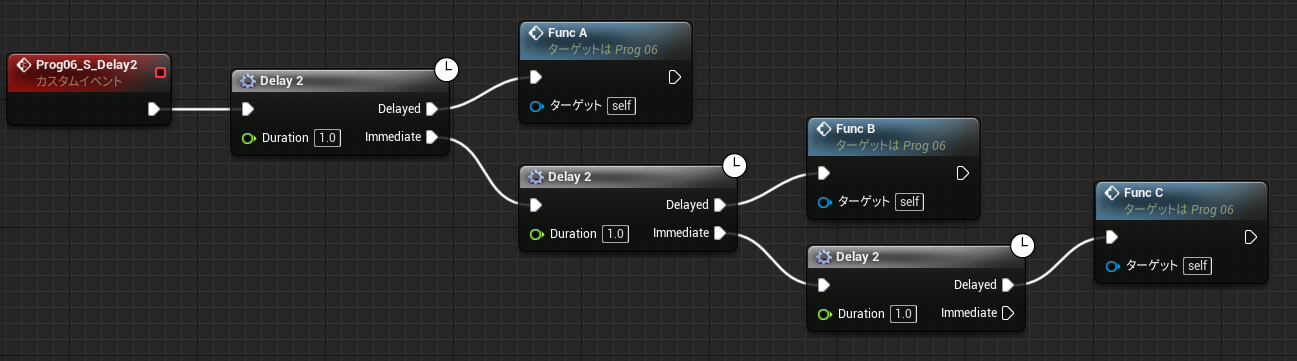
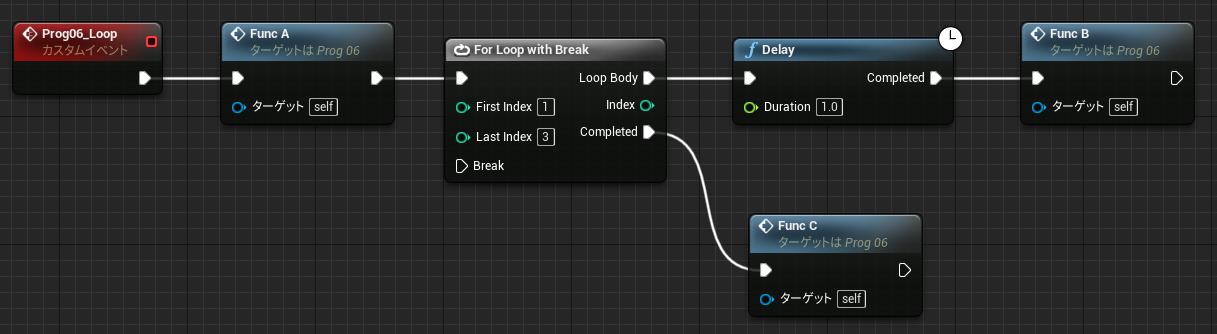
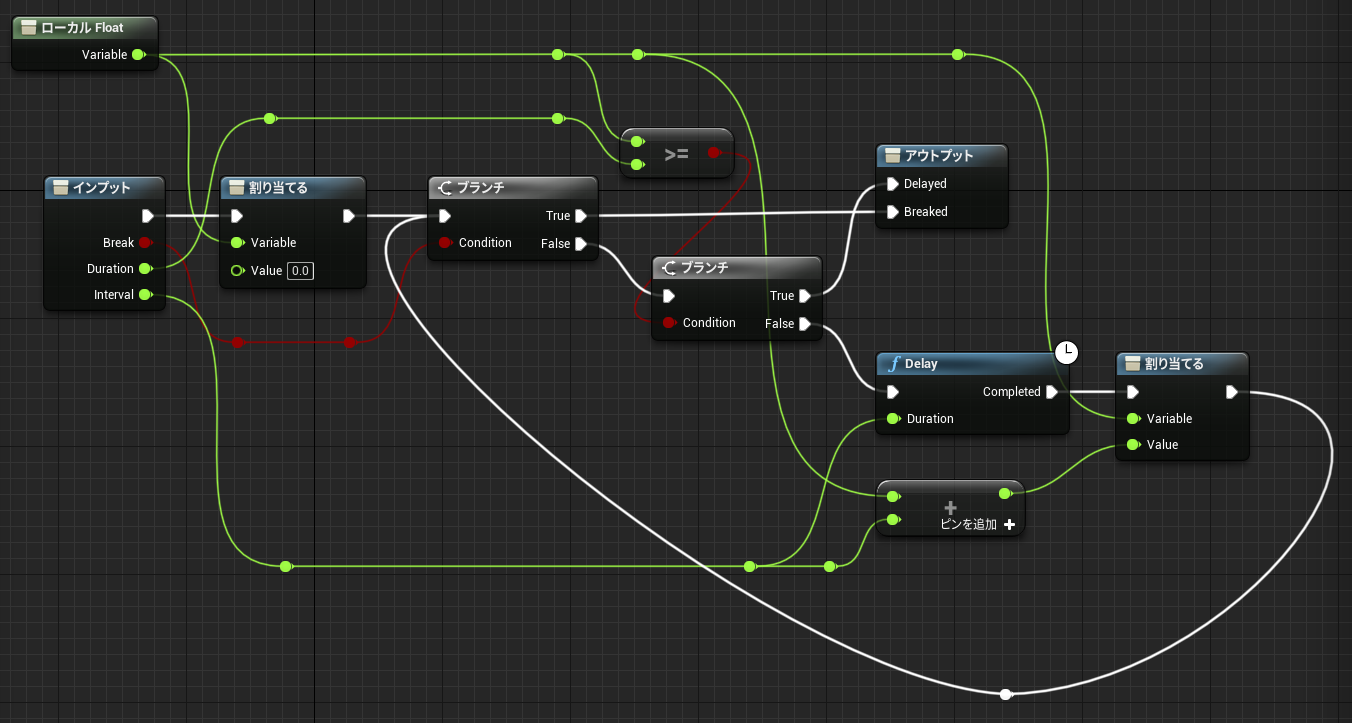
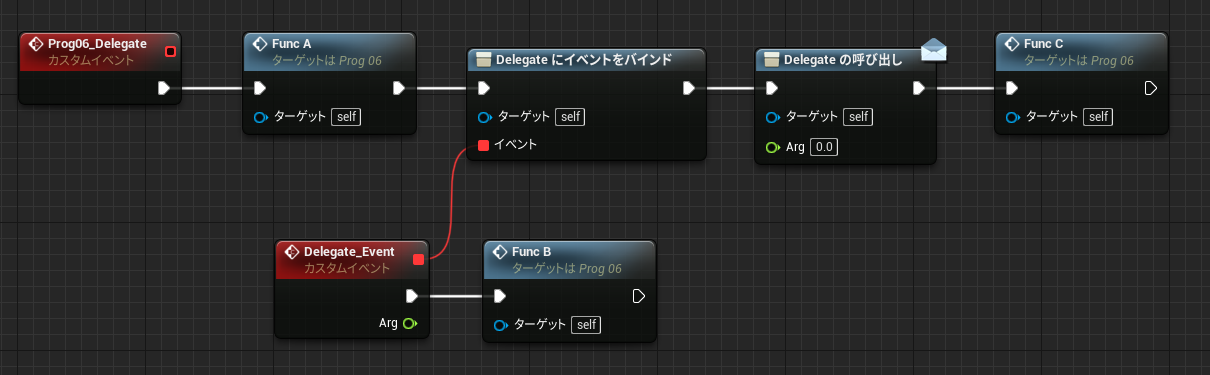
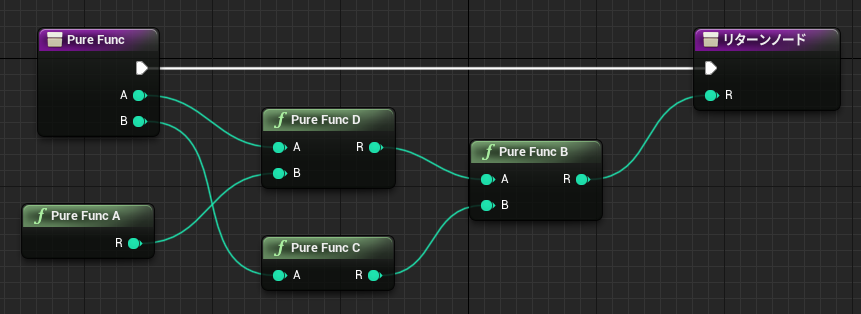
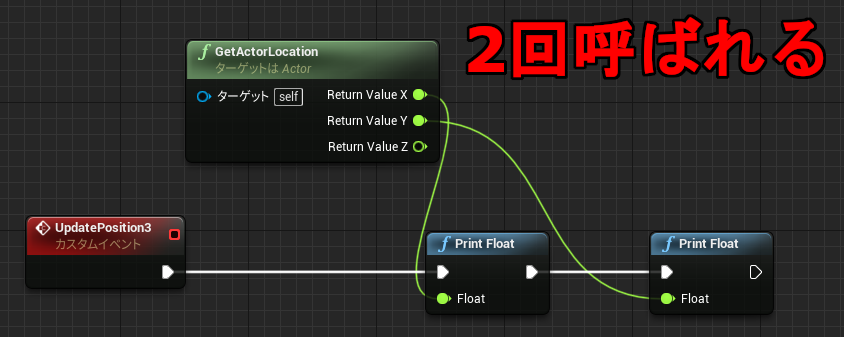
イベントグラフでは複数のイベントのノードを同時に記述できるため、全く関係ないノードの値を参照することもできてしまいます。(↓不正参照に見える例A)
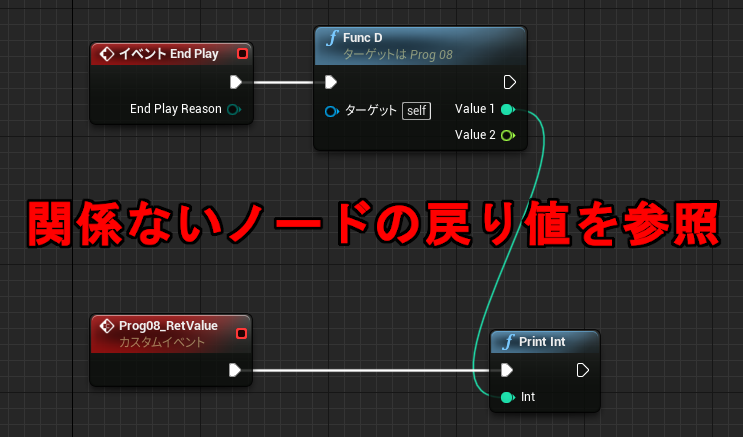
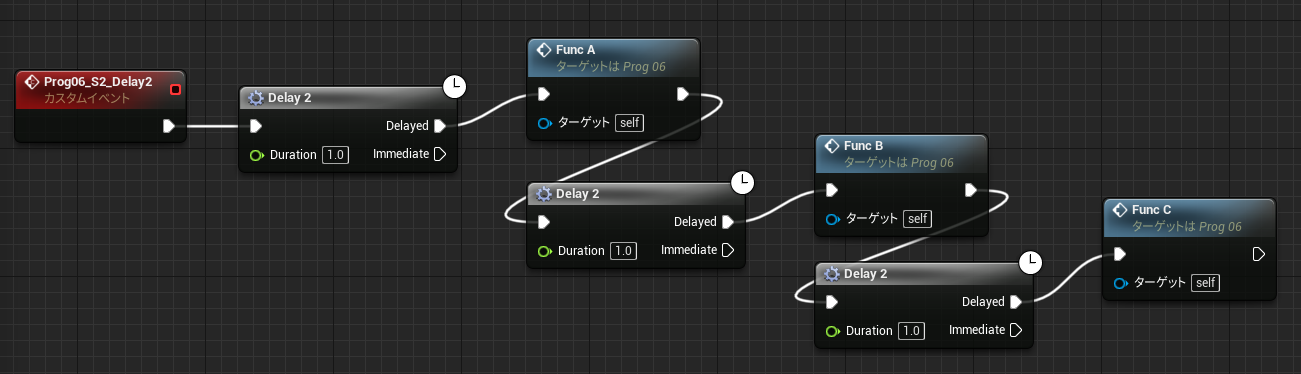
↑PrintInt が FuncD 関数の戻り値を参照しています。流れと無関係なスコープ外の参照であり、FuncD の実行前に戻り値を参照することになります。動きが予想できないのですが、実行そのものは問題なくできてしまいます。その理由を Delay 命令の動きから考えてみます。
Delay は即座に呼び出し元に Return しており、後続の命令はあとから別のコンテキストで実行します。(前回の解説参照) 下記のコードはよくある普通のものですが、よく見ると中断前に実行した関数 FuncD の結果を時間差で参照していることになります。もちろん PrintInt では正しく FuncD の結果を読み取ることができます。
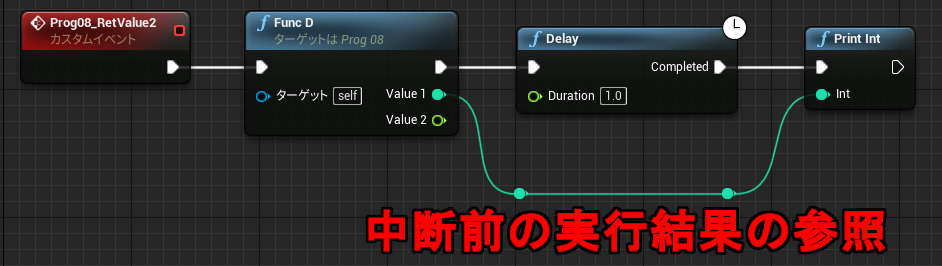
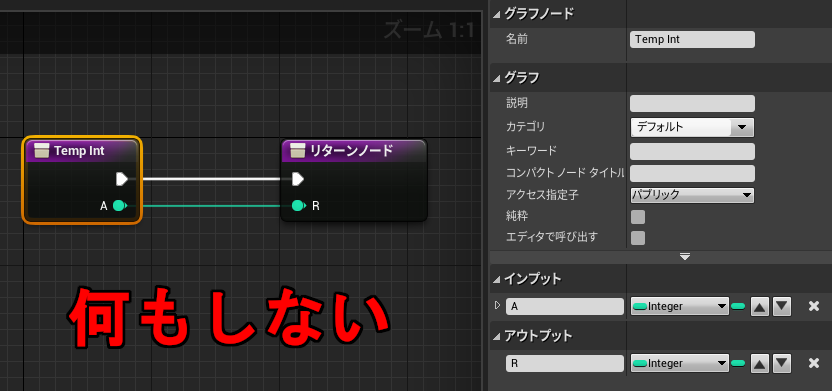
初回で触れたように、通常の関数の戻り値は必ず一時変数を経由します。イベントグラフでは途中で中断&再開される可能性があるので、通常の変数だけでなくこのような「戻り値を格納している無名の一時変数」もメンバとして保存しておく必要があります。
これらの違いを C++ 風のコードで表現してみます。(あくまで説明用のもので、実際の UE4 C++ のコードではありません)
Blueprint の Delay の挙動を C++ で表すと下記のとおりです。
// 動作イメージ
void Prog08_RetValue2()
{
int tempA= FuncD().Value1;
AddDelayAction( 1.0f, [=](){
PrintInt( tempA );
} );
}
Blueprint では C++ のように Lambda で変数の値をキャプチャできないので、下記のようにメンバ変数を経由します。
// Blueprint の挙動
class Prog08 {
int TempA= 0; // 関数の結果を受け渡す一時変数
public:
void Prog08_RetValue2()
{
TempA= FuncD().Value1; // 関数の結果をメンバに格納
AddDelayAction( 1.0f, [this](){
PrintInt( TempA ); // メンバのアクセスは可能
} );
}
};
よって最初の不正参照に見える例Aも、実際は戻り値が格納されるメンバ変数を読み取っていることになります。本来なら命令を実行したあとに結果が格納されるのですが、まだ実行していないため初期値(0)が入ります。
class Prog08 {
int TempA= 0;
public:
void EndPlay()
{
TempA= FuncD().Value1;
}
void Prog08_RetValue()
{
// 戻り値が入るメンバ変数を読み取っている
// EndPlay() 実行前に参照しても特に問題はない
PrintInt( TempA );
}
};
全く同じように、イベントの引数もメンバとして確保されているため関係ないところから参照することができます。
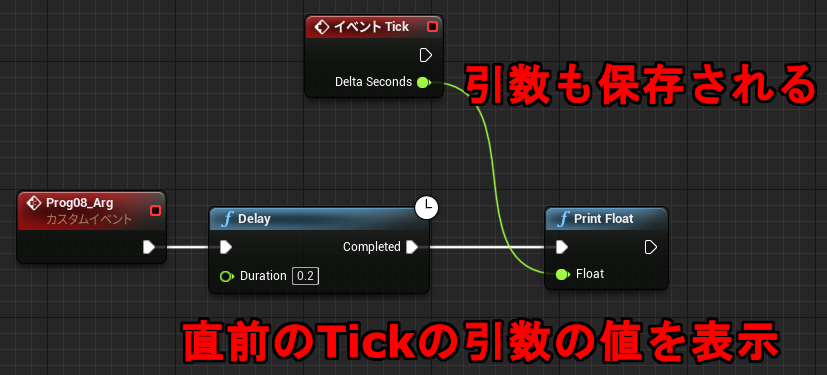
↑Tick の値を読み取る。初回は 0、以降は最後の tick の引数値が入る。C++ イメージだと下記の通り。
class Prog08 {
float DeltaSeconds= 0.0f;
public:
void Tick( float delta_seconds )
{
DeltaSeconds= delta_seconds;
}
void Prog08_Arg()
{
PrintFloat( DeltaSeconds ); // 別の関数の引数の参照
}
};
もちろん、問題なく動くとはいえ実行前の戻り値や他のイベントの引数に依存するようなコードは避けた方が良いでしょう。
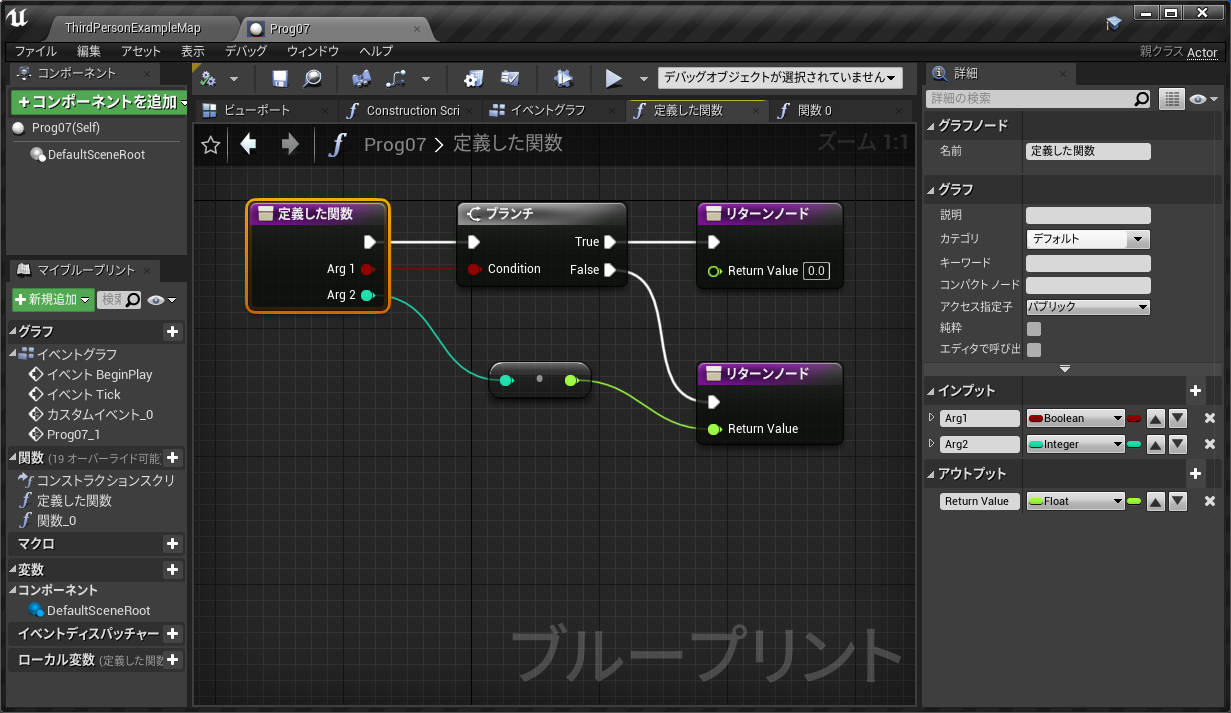
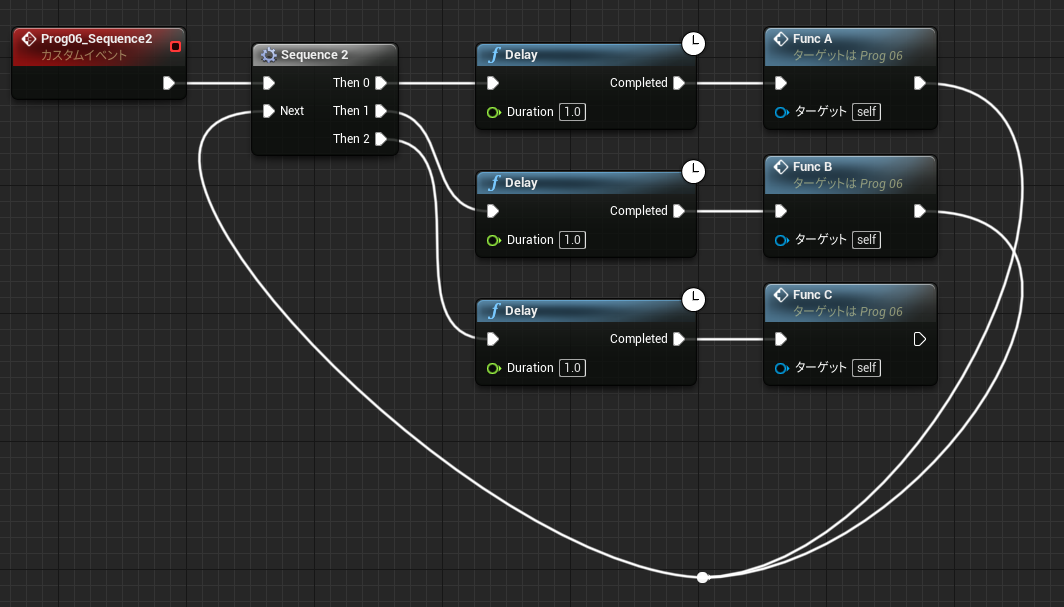
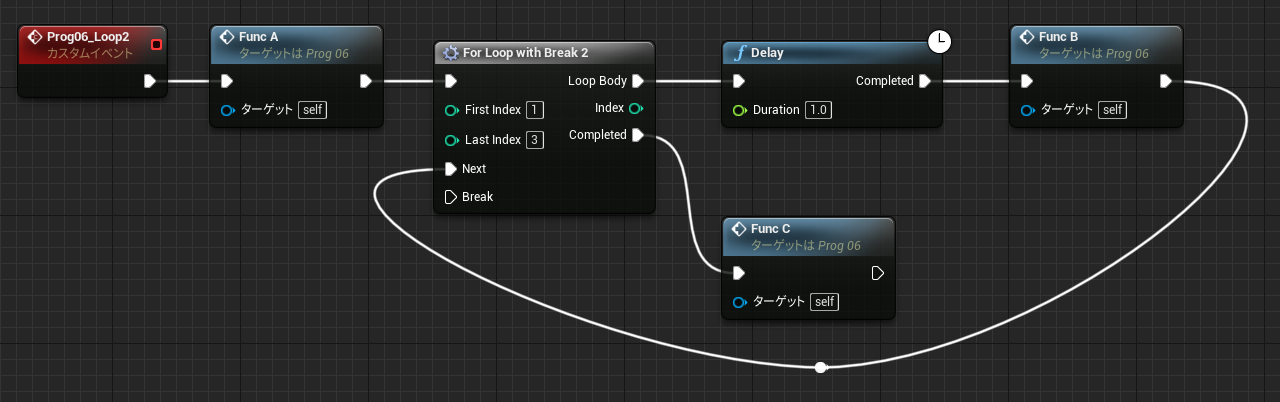
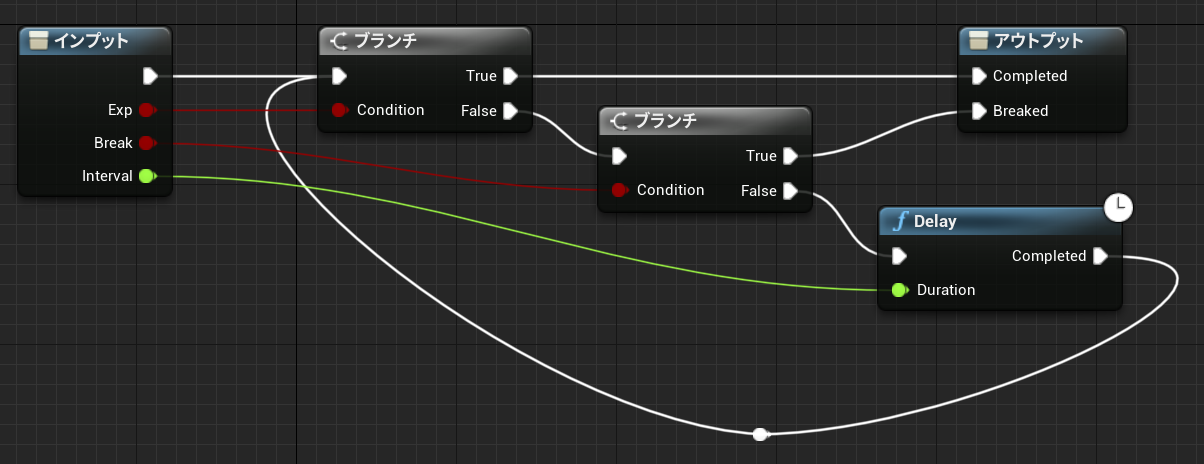
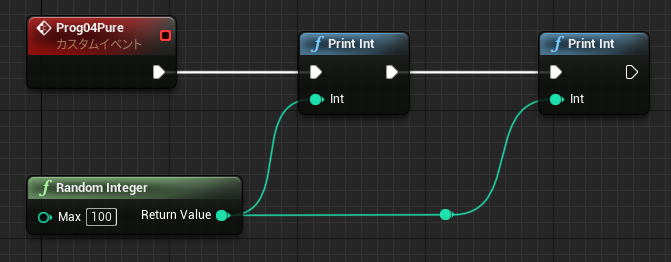
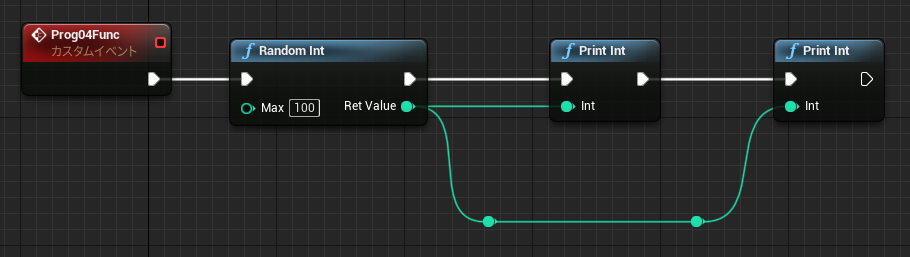
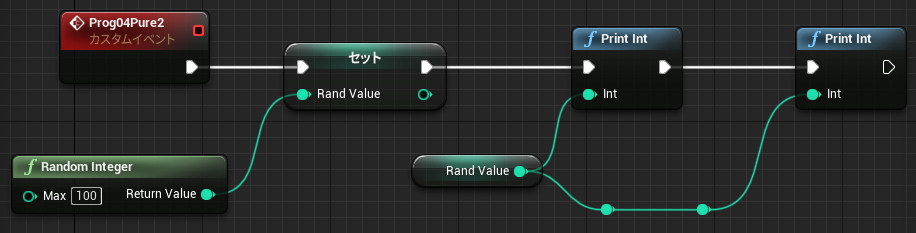
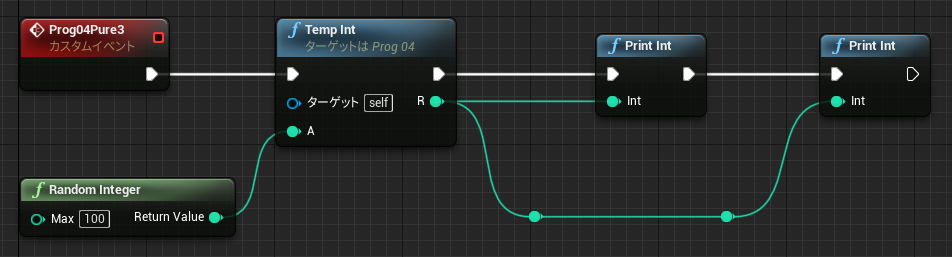
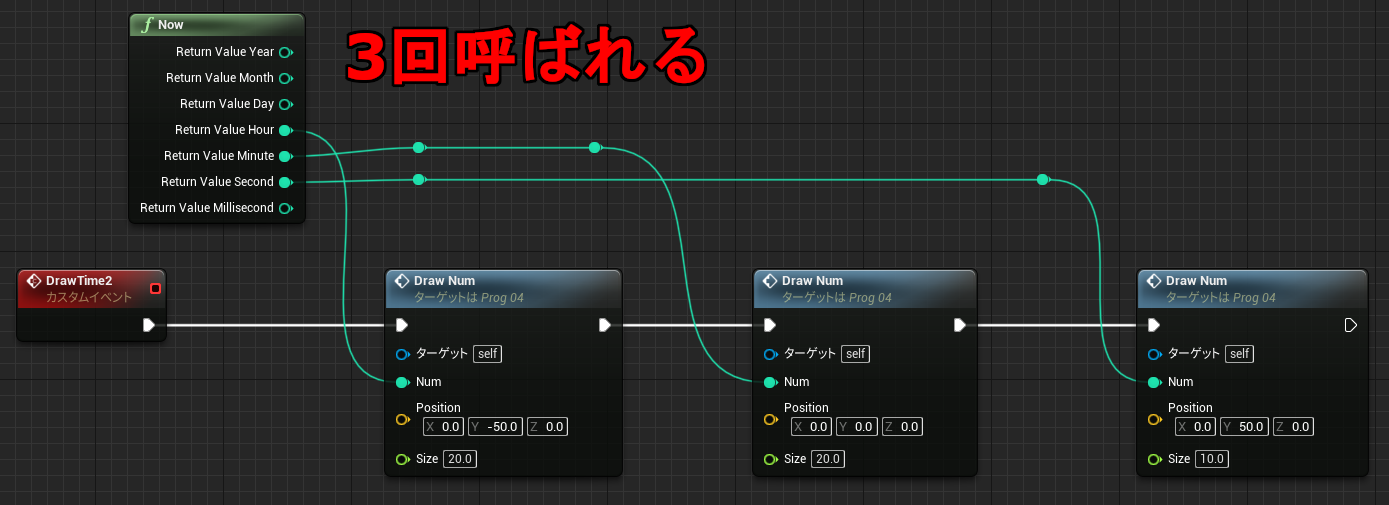
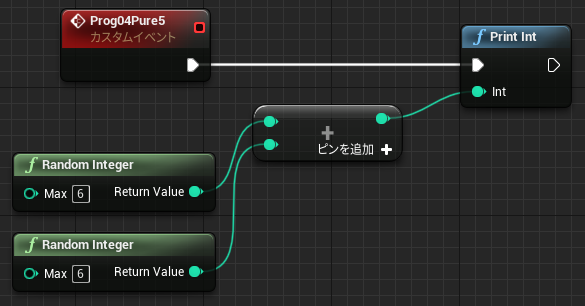
なお中断を考慮する必要がない関数グラフの場合も、未実行ノードの値を参照することができます。関数の場合メンバとして保存する必要がないので、一時変数はローカル変数(stack)に割り当てられています。
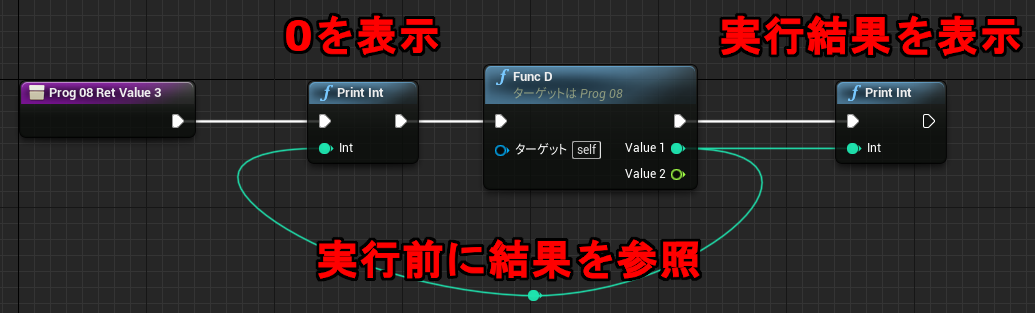
↑最初の PrintInt は 0 を表示し、次の PrintInt は FuncD の戻り値を表示します。
●配列と値のコピー
他の多くの言語と同じで UE4 のオブジェクトは参照として扱います。そのオブジェクトが UObject である限り生存期間は GC が管理します。
Vector や Rotator などの基本型はもちろん、構造体は参照でなく値として扱います。変数への代入はコピーです。
配列やマップ、セットなどのコンテナは、Blueprint の場合オブジェクトではなく値として扱われます。変数への代入は構造体と同じようにまるごと複製が行われます。
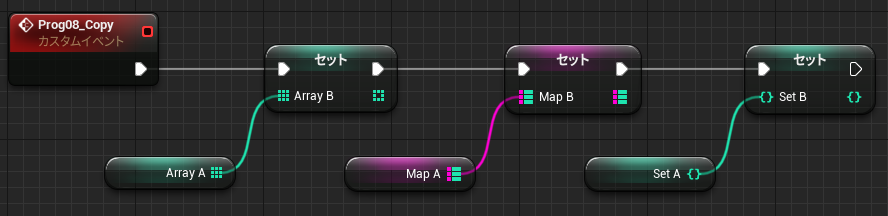
↑ArrayA と ArrayB は異なる配列になる。Map, Set も同じ。
関数の引数や戻り値もそのままだとコピーになるため、配列が巨大な場合は負荷が高くなります。その回避策として Blueprint では引数にリファレンス渡し(参照渡し)を指定することができます。
↓引数定義の下に「リファレンス渡し」のチェックボックス

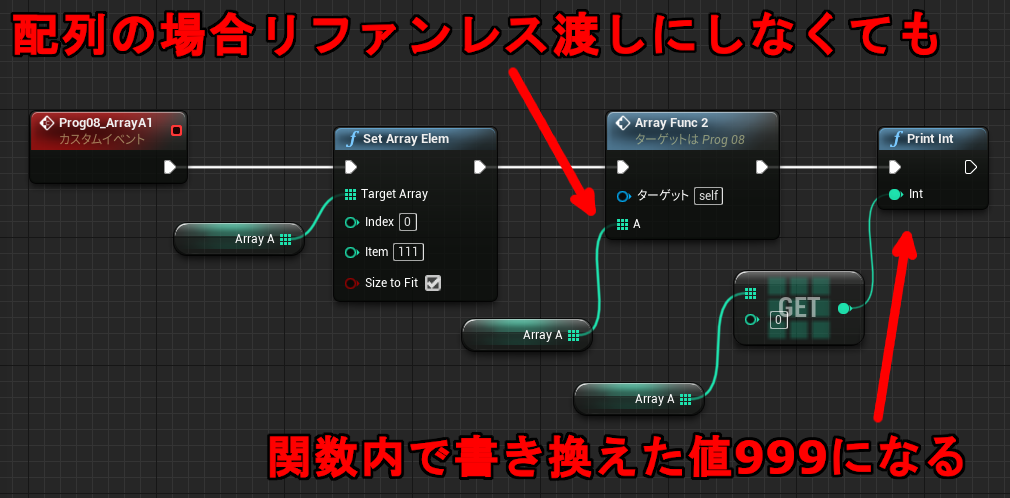
使用例
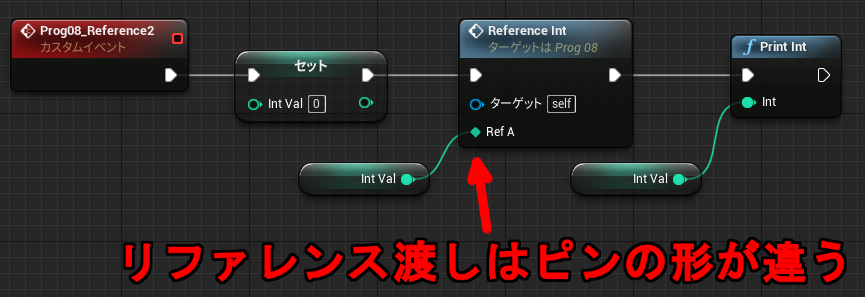
↑関数内で書き換えた結果が呼び出し元の変数に反映されるため 111 が表示されます。
LogBlueprintUserMessages: [None] 111
リファレンス渡しはパラメータをコピーしません。また書き換えた結果が呼び出し元に反映されるので、戻り値をコピーで返す必要もなくなります。よって何度も複製が発生するのを防ぎます。巨大な配列や巨大な構造体を関数に渡す場合に効率的です。
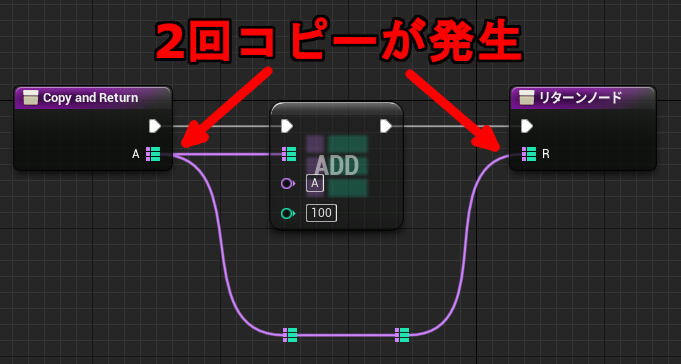
↓通常の値渡しの場合
↓リファレンス渡しの場合
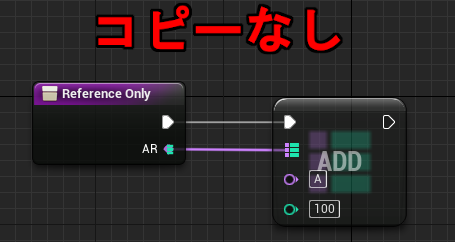
ところが Blueprint の場合、パラメータのリファレンス渡しが意図した通りに動かないケースが少なくありません。そのため引数で配列を渡すことを禁止したり、パラメータのリファレンス渡し機能自体を信用していないことが多いのではないかと思います。というのも、UE4 Editor 上のパラメータの「リファレンス渡し」のチェックボックスは無視される場合が多いからです。
1. イベントの引数は「リファレンス渡し」できない。
2. 関数の引数は配列の場合常に「リファレンス渡し」になる。
3. 関数の引数は配列以外では「リファレンス渡し」のチェックボックスに従う。
上の 1. 2. に当てはまるケースでは「リファレンス渡し」のチェックボックスの設定が無視されます。
コピーを減らして効率化しようと思ったのに無駄なコピーが何度も行われていたり、書き換えた結果を返そうと思ったのに反映されていなかったりと混乱やバグの原因になりがちです。
また配列の場合は、変更するつもりがなかったのに内容が書き換わってしまう場合があります。
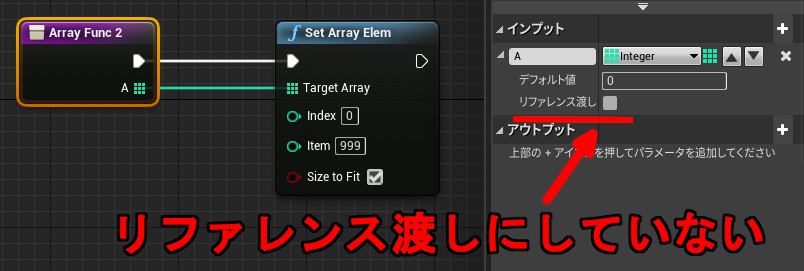
↑この挙動は配列の場合だけです。同じコンテナでもマップ、セットはデフォルトで値渡しになるため呼び出し元のデータは書き換わりません。配列と同じように関数内の変更を反映させたい場合は「リファレンス渡し」を有効にする必要があります。
配列と異なり、マップ、セットはあとから追加された比較的新しい機能です。配列の挙動だけ異なっているのはおそらく互換性のためだと思われます。
・よくわからないときは「リファレンス渡し」機能は使わない
・カスタムイベントでは引数に巨大なコンテナを渡してはいけない
代わりに使えるなら関数にする、または直接変数をアクセスするように変更する
・関数の中で引数で渡された配列を書き換えるときは注意
逆に十分理解して使えば、リファレンス渡しは大変強力な機能になります。
●イベント引数を「リファレンス渡し」にできない理由
イベントグラフでパラメータの「リファレンス渡し」が使えない理由は、途中で中断&再開する可能性があるからです。イベントグラフではローカル変数が使えず、命令の戻り値も無名のメンバ変数として保存されています。イベントの引数もメンバ変数になります。
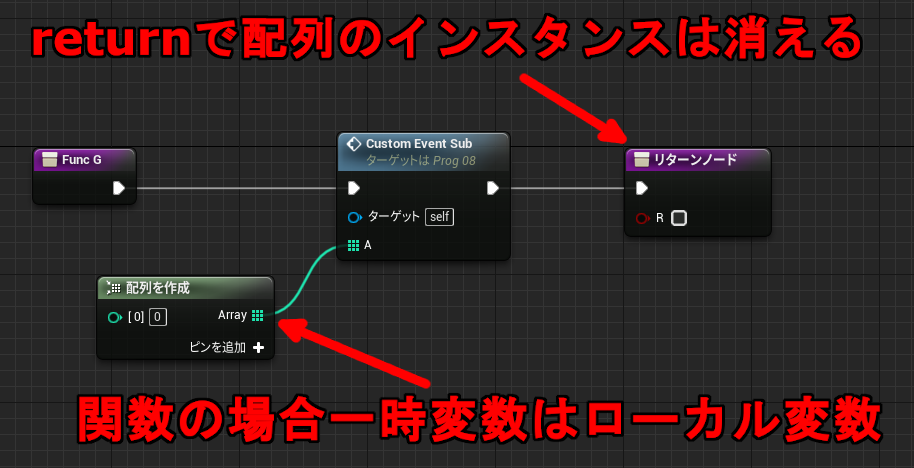
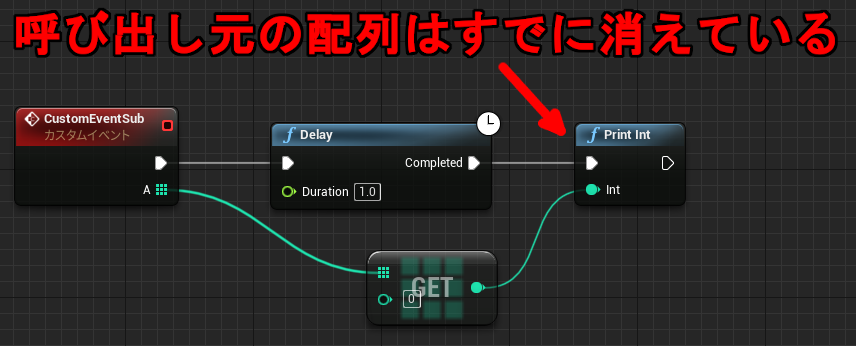
このメンバ変数は、中断したあとも時間差で異なるコンテキストからアクセスする可能性があるため、リファレンス(ポインタ)で保持することができません。例えば下記のような場合、Delay のあとでは呼び出し元の配列のインスタンスがすでに無くなっています。もしリファレンス渡しが使えていたら不正なメモリをアクセスすることになります。
イベントのインタフェースを C++ で定義した場合は引数をリファレンス(参照)渡しで宣言できますが、Blueprint で実装すると内部で中でコピーが行われるため同じです。
イベントグラフでは定義したカスタムイベントを RPC に変換することができます。Network を通した呼び出しではリファレンス引数も常にコピーされるので、仕様を統一する意味もあるのかもしれません。
●マクロ外でローカル変数を使う
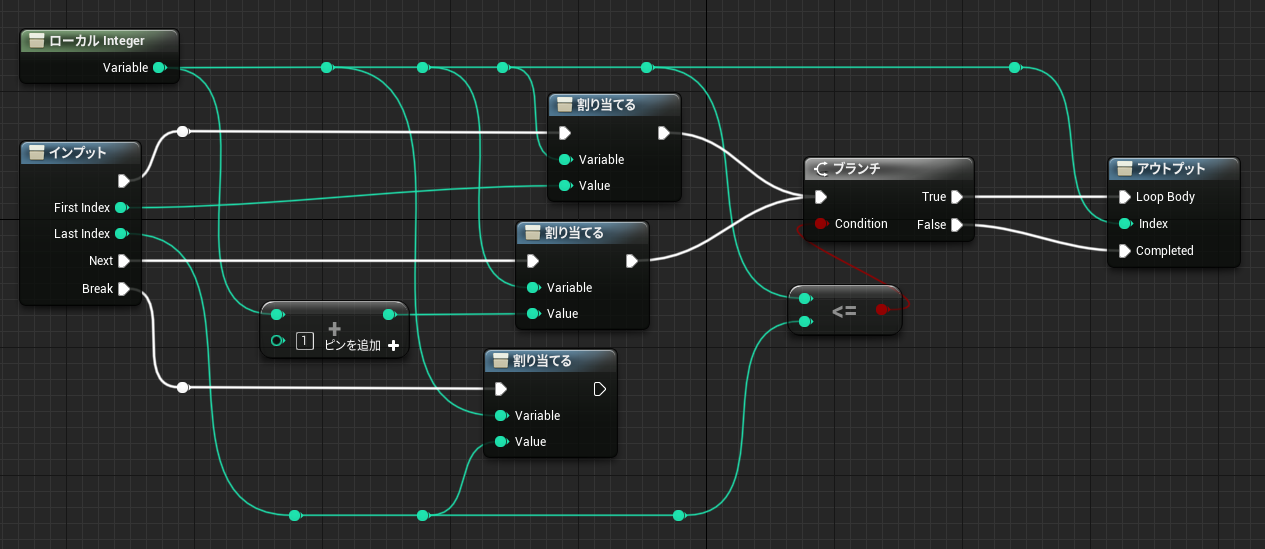
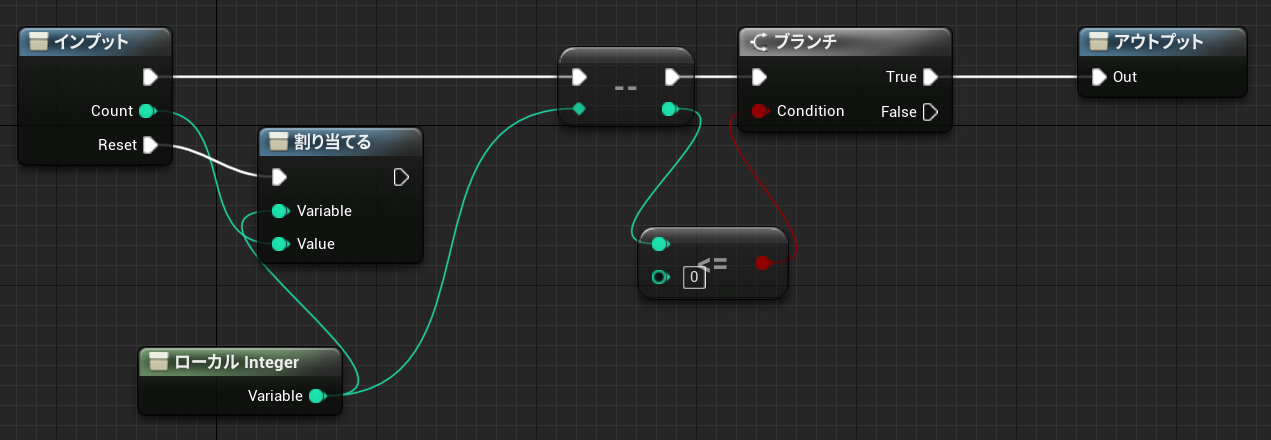
マクロ定義の中では無名のローカル変数を使うことができます。このローカル変数は関数内で定義できるものとは別物で、スタック上に確保されるわけではなく名前の衝突を防ぐ目的で使われます。
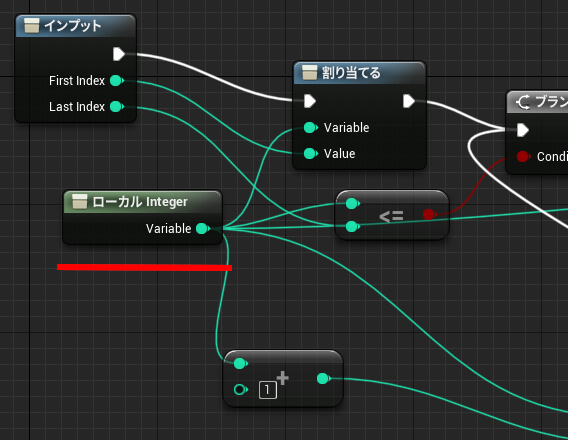
↑ForLoop マクロで使われているローカル変数「ローカルInteger」
今回説明した要素を組み合わせると、実はマクロの外でもこの無名のローカル変数を使えることがわかります。実用はおすすめしませんが、Blueprint の挙動の理解につながると思いますので説明してみます。
関数の戻り値は変数に束縛されており無名の左辺値になります。そのため参照を受け取る関数の引数にそのまま渡すことが可能です。この左辺値である「関数の戻り値」をローカル変数として利用することができます。
↓まず適当な整数値を返す関数を定義する
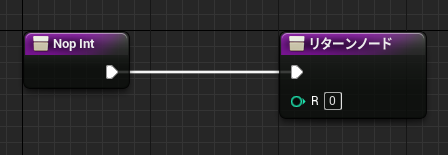
この NopInt の戻り値がマクロ内の「ローカルInteger」ノードと同じ働きをします。Pure ではない関数なら何でも構いません。
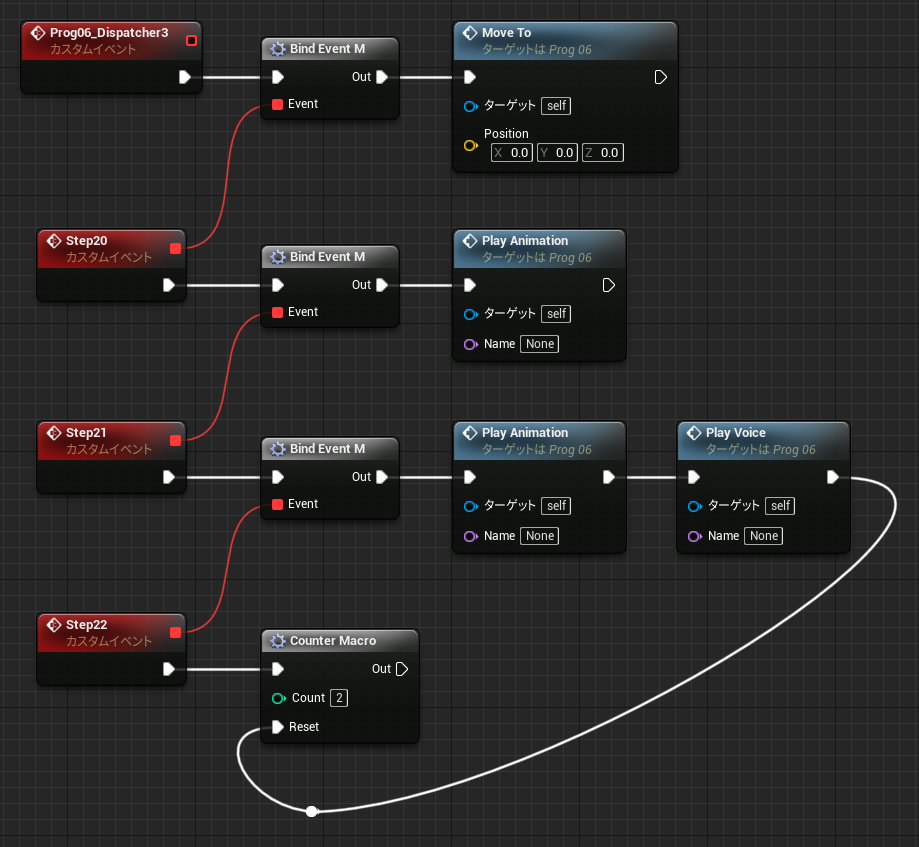
使用例
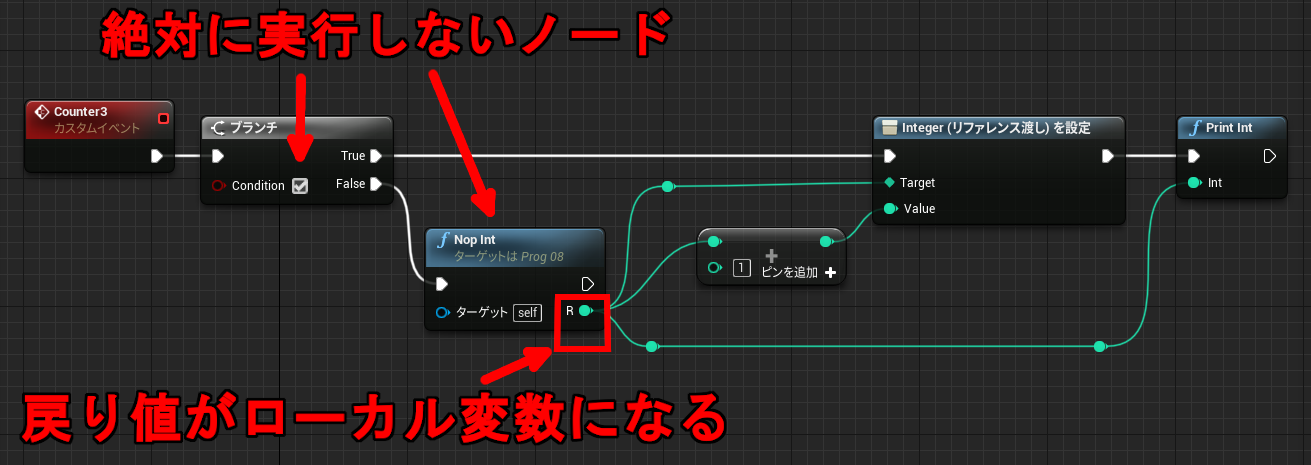
↑変数(プロパティ)を消費せずに、加算し続ける値を表示することができます。Counter3 は呼び出すたびに値が 0 → 1 → 2 と増えていきます。branch を使ってるのは絶対に実行しないノードを作るためです。実行すると変数の値が上書きされます。
ローカル変数の値を書き換えるには「Integer(リファレンス渡し)を設定」を使います。もちろん Integer 以外の型も使えます。
実は Pure 関数の戻り値もリファレンス渡しの引数に渡せるので左辺値扱いなのですが、関数を参照するたびに毎回呼ばれるのですぐ値が上書きされてしまいます。そのためローカル変数の用途には向きません。
●イベントグラフと配列の生存期間
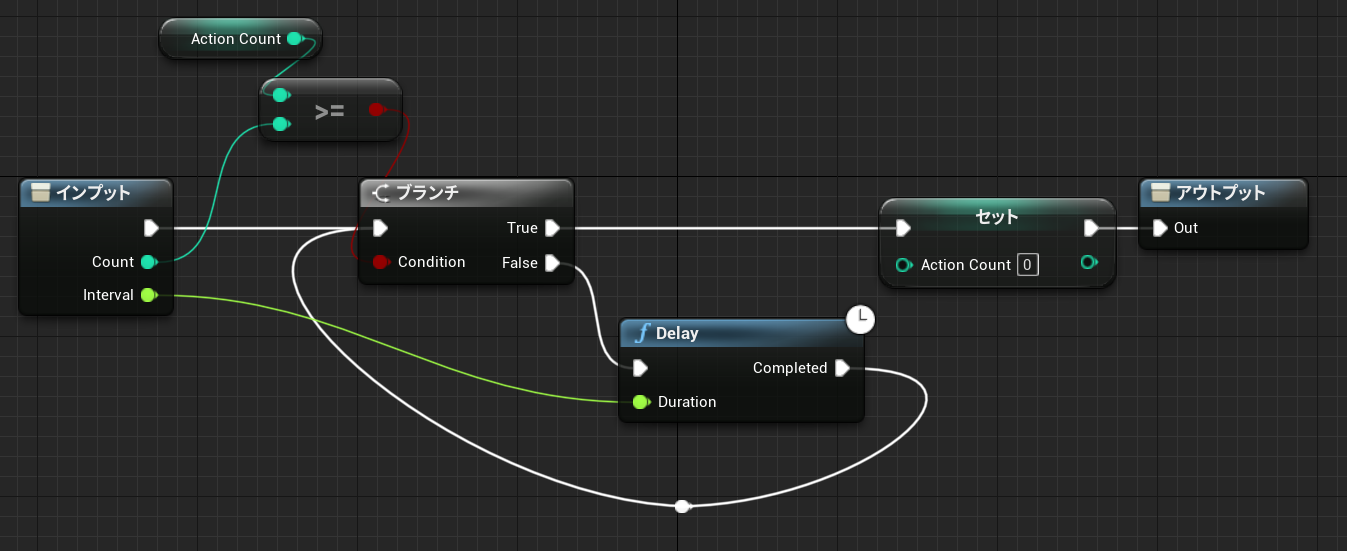
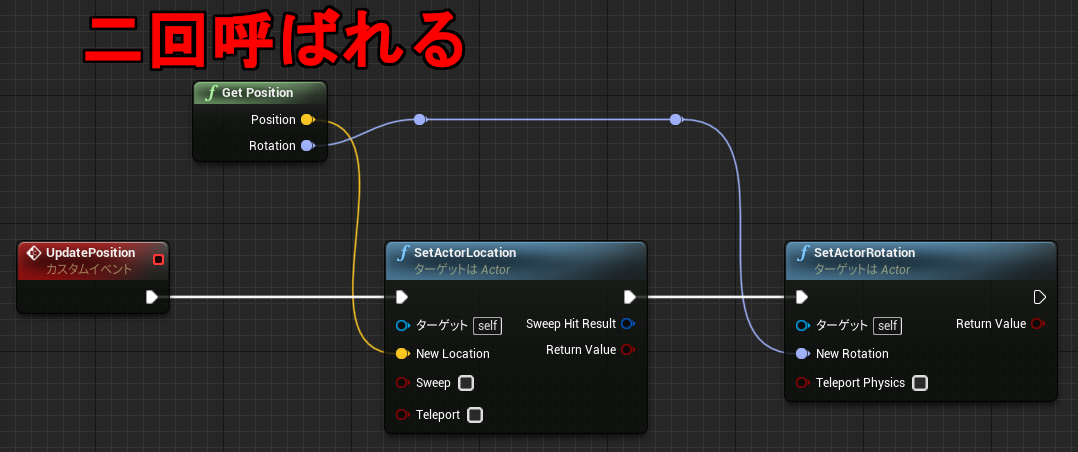
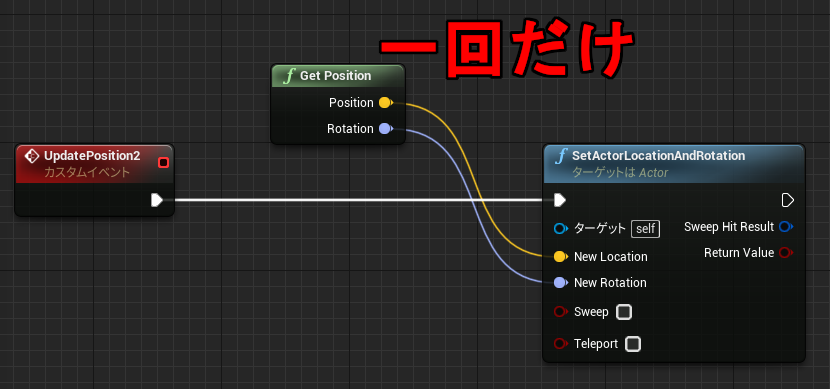
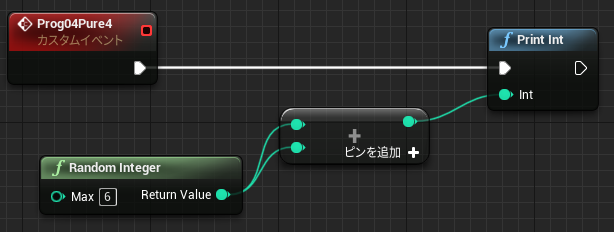
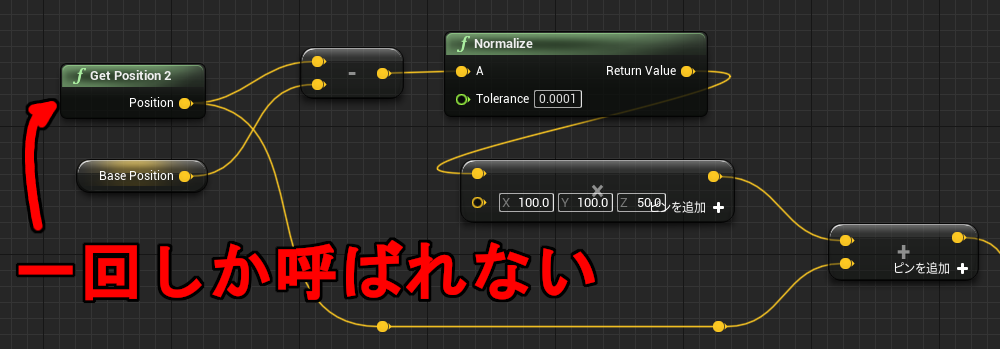
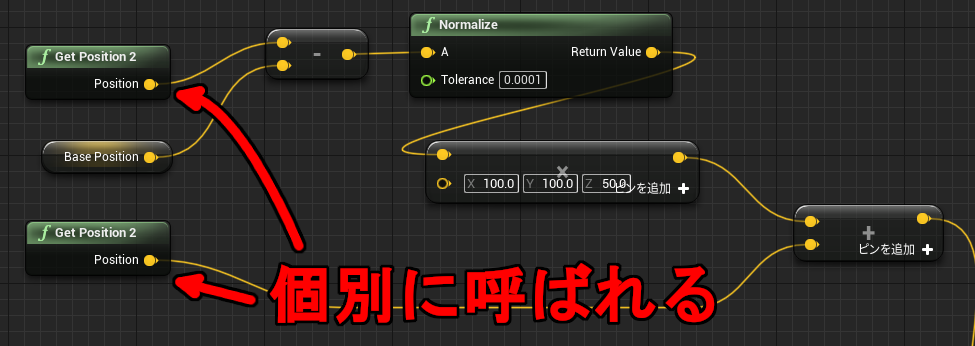
「配列を作成」は動的に生成した配列を返します。この命令は Pure 関数なので、最初に変数へ保存しておかないとすぐにアクセスできなくなります。例えば下記のように 2回参照を行うと、それぞれ別の配列が作られることになります。
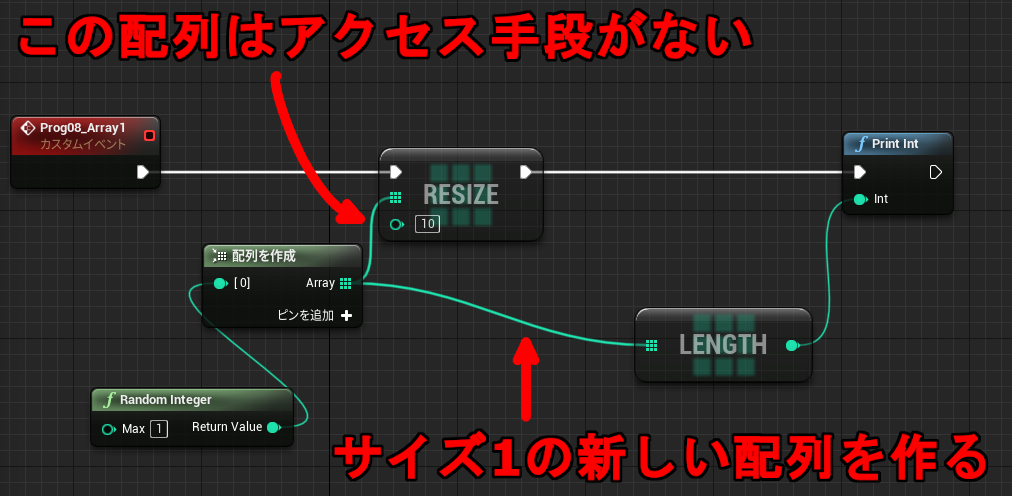
↑1が表示される。
リサイズしたサイズ10の配列はアクセス手段を持ちません。同じ Pure ノードを2回呼び出したので、サイズ 10の配列は 2回目の呼び出しで上書きされます。RandomInteger は Int 型を指定しているだけで特に意味はありません。
イベントグラフの場合、戻り値や引数など無名の一時変数はメンバ変数なので、実行が終わっても値が残り続けます。
下記の例はおよそ 1GB の配列を作成したときのメモリ使用量の変化です。

↑関数グラフの場合一時変数がローカル変数(stack)なので、実行が終わるとすぐにメモリが解放されます。
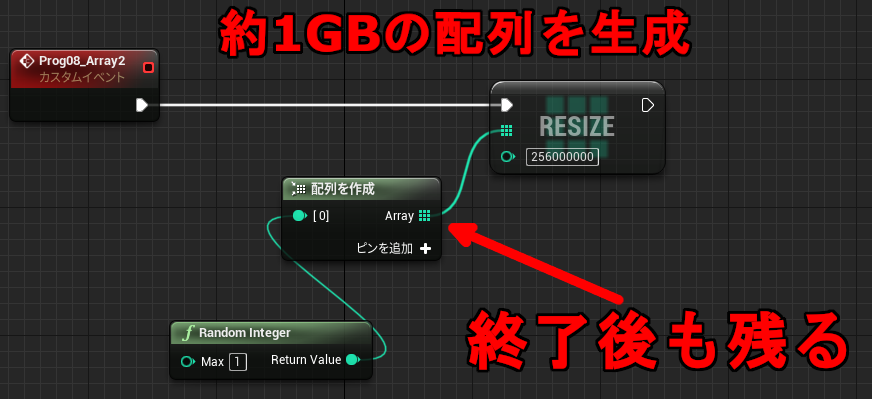

↑イベントグラフの場合一時変数が無名のメンバとして残るため、実行が終わってもメモリが解放されずに残り続けます。
意図せずにメモリを消費している可能性があるので注意が必要です。
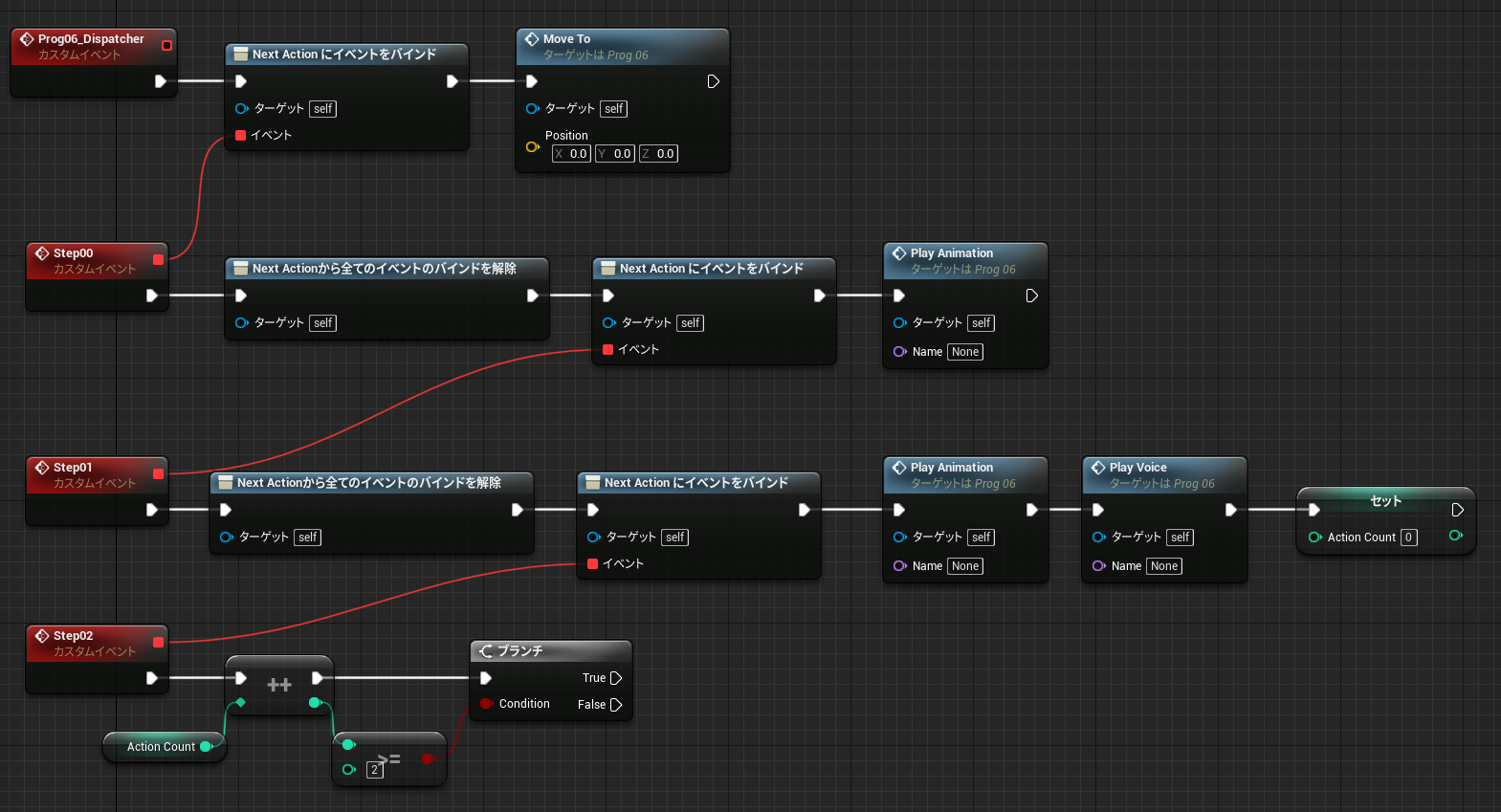
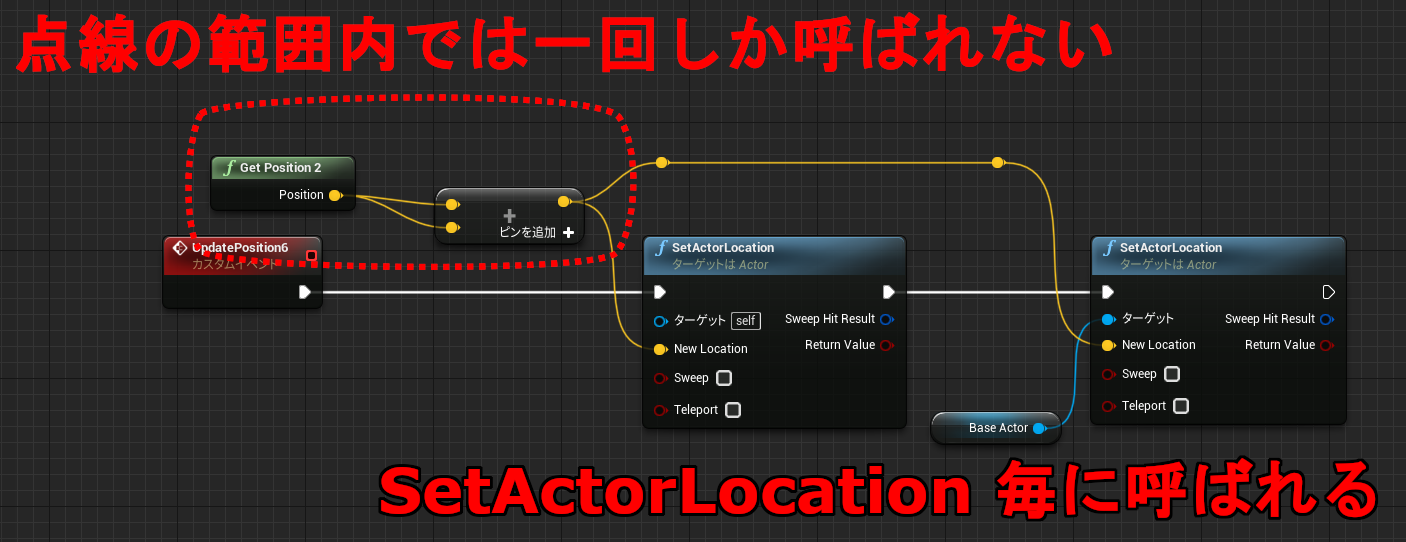
複数の命令を経由する場合は更に問題が大きくなります。イベントグラフの引数やノードの戻り値毎に複製が残るためです。
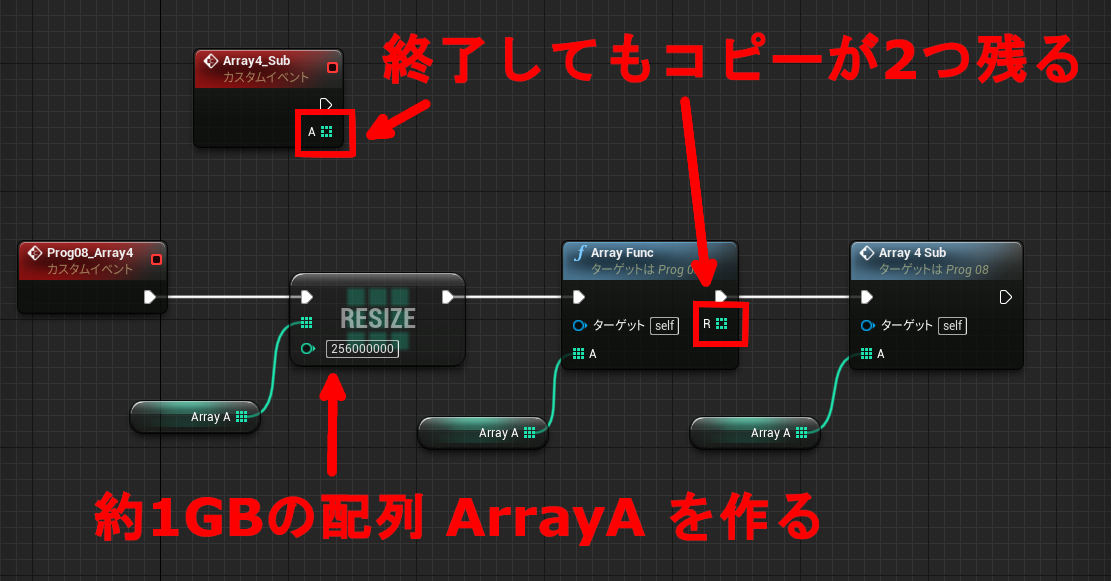
↑1GB の配列が 3つ作られ実行後も残り続ける。ArrayFunc は何もしないで引数を返すだけの関数。
実際に走らせてみると、最初のリサイズ後の消費メモリ 3.4GB、ArrayFunc, Array5_Sub 呼び出し後は 5.4GB になりました。イベントグラフではこのように、Blueprint の一時変数がメモリを無駄に消費し続ける可能性があります。
容量が極端に大きいコンテナ(配列、マップ、セット)を Blueprint で扱う場合は、一時変数の生存期間に十分注意してください。
●イベントグラフの無名変数と UObject の生存期間
UObject は GC が管理するため、配列の参照とは異なり生存期間を気にする必要がありません。ただし UObject を所有できるのはプロパティ(UPROPERTY, FProperty)に限られます。
イベントグラフのノードの引数や戻り値は無名のメンバ変数にコピーされますが、オブジェクトはそのまま参照で保持します。UObject が Blueprint の一時変数上にしかない状態で、生存期間が延命されるかどうか調べてみます。つまりイベントグラフの一時変数がプロパティ扱いかどうかがわかります。
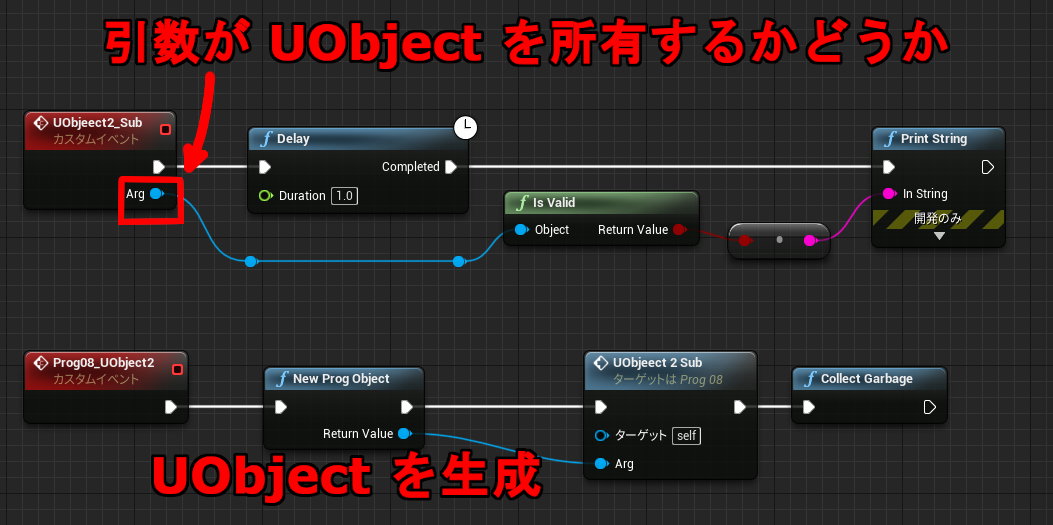
Blueprint では直接 UObject を生成する命令がないので、NewProgObject は C++ で実装しています。作成したダミーの UObject を返します。Prog08_UProject2 は Object が一時変数上にしかない状態で Collect Garbage を呼び出しています。
Collect Garbage は実際はフラグを立てるだけで、このタイミングでは GC が走りません。フラグを見てフレーム内の決まったタイミングで GC が呼ばれるため、結果を調べたいときは数フレーム待つ必要があります。
実際に走らせてみると結果は false でした。つまり UObject2_Sub 最後の PrintString のタイミングでは Object は無効であり GC によって削除されています。
LogBlueprintUserMessages: [Prog08_2] false
このことから Blueprint の無名の一時変数はプロパティではなく TWeakObjectPtr 相当になっていることがわかります。そのためイベントグラフが配列のようにオブジェクトを所有し続けてしまうことはありません。UObject を有効なまま保持したい場合は、明示的に変数(プロパティ)に格納しておく必要があります。
ところが Blueprint を Native 変換すると挙動が変わることがわかりました。(UE4 4.25.1) 下記のように一時変数が UPROPERTY 宣言されています。
// Prog08__pf3730294777.h から抜粋
UPROPERTY(Transient, DuplicateTransient, meta=(OverrideNativeName="K2Node_CustomEvent_Arg"))
UProgObject* b0l__K2Node_CustomEvent_Arg__pf;
// Prog08__pf3730294777.cpp から抜粋
void AProg08_C__pf3730294777::bpf__UObjeect2_Sub__pf(UProgObject* bpp__Arg__pf)
{
b0l__K2Node_CustomEvent_Arg__pf = bpp__Arg__pf;
bpf__ExecuteUbergraph_Prog08__pf_34(46);
}
Native 変換した状態で走らせるとは結果は true となり、UObject は消えていませんでした。
[2020.07.12-05.01.36:883][ 96]LogBlueprintUserMessages: [Prog08_2] true
配列と同じようにメモリ上にオブジェクトが残り続ける可能性があるため注意が必要です。Blueprint と挙動が異なるため、今後仕様が変更される可能性があります。
●プログラミング言語 Blueprint
言語仕様に焦点を当てて解説してきましたが、Blueprint については今回で一旦終了したいと思います。また何か説明できることがあれば続きを書くかもしれません。
Blueprint だけでゲームを作ることもできます。理解して使えばいろいろ応用もできて面白い言語ですので、プログラマの方にも興味を持っていただければと思います。
関連エントリ
・UE4 プログラミング言語 Blueprint (2)
・UE4 プログラミング言語 Blueprint (1)
・4倍速い Ryzen 9 3950X の UE4 コンパイル速度
・UE4 UnrealBuildTool の設定 BuildConfiguration.xml
・UE4 UnrealBuildTool VisualStudio の選択を行う
・UE4 UnrealBuildTool *.Build.cs のコードを共有する