Direct3D 10 の Shader4.0 は、実行可能な命令スロットも多いし
整数型も整数演算も扱えるし、HLSL を使うと Shader であることを
忘れそうになります。
条件分岐やループ命令等もそのまま記述し、当たり前のように実行
できるようになりました。
例えばまったく意味のない内容ですが、VertexShader の最後に
わざとこんなコードを書いてみます。
Out.Normal= 0;
for( int i= 0 ; i< 200 ; i++ ){
Out.Normal+= In.Normal;
Out.Normal+= wpos;
}
描画するデータは次のとおり。
・Teapot (Maxのプリミティブ)
・ポリゴン数 57600
・頂点数 29646
Pixel の影響をできるだけ受けないように、PixelShader は固定の
定数を return するだけとし、描画面積も点に近い状態でテストします。
実行するとさすがに時間がかかって、GPU 時間で 1410 usec ほど
消費しました。(GeForce8800GTS 640)
コンパイルされたコードはこんな感じです。命令コードに loop 命令が
あって、本当に Shader 内でループ実行されていることがわかります。
vs_4_0
dcl_input v0.xyz
dcl_input v1.xyz
dcl_output_siv o0.xyzw , position
dcl_output o1.xyz
dcl_constantbuffer cb0[8], immediateIndexed
dcl_constantbuffer cb1[3], immediateIndexed
dcl_temps 3
mov r0.xyz, v0.xyzx
mov r0.w, l(1.000000)
dp4 r1.x, cb1[0].xyzw, r0.xyzw
dp4 r1.y, cb1[1].xyzw, r0.xyzw
dp4 r1.z, cb1[2].xyzw, r0.xyzw
mul r0.xyzw, r1.yyyy, cb0[5].xyzw
mad r0.xyzw, cb0[4].xyzw, r1.xxxx, r0.xyzw
mad r0.xyzw, cb0[6].xyzw, r1.zzzz, r0.xyzw
add o0.xyzw, r0.xyzw, cb0[7].xyzw
mov r0.xyzw, l(0,0,0,0)
loop
ige r1.w, r0.w, l(200)
breakc_nz r1.w
add r2.xyz, r0.xyzx, v1.xyzx
add r0.xyz, r1.xyzx, r2.xyzx
iadd r0.w, r0.w, l(1)
endloop
mov o1.xyz, r0.xyzx
ret
// Approximately 19 instruction slots used
元のソースコードに loop 展開のアトリビュートを次のように追加すると
Out.Normal= 0;
[unroll] // attribute
for( int i= 0 ; i< 200 ; i++ ){
Out.Normal+= In.Normal;
Out.Normal+= wpos;
}
145 usec と実行時間が一気に 1/10 になりました。
出力コードを見てみると・・
vs_4_0
dcl_input v0.xyz
dcl_input v1.xyz
dcl_output_siv o0.xyzw , position
dcl_output o1.xyz
dcl_constantbuffer cb0[8], immediateIndexed
dcl_constantbuffer cb1[3], immediateIndexed
dcl_temps 3
mov r0.xyz, v0.xyzx
mov r0.w, l(1.000000)
dp4 r1.y, cb1[1].xyzw, r0.xyzw
mul r2.xyzw, r1.yyyy, cb0[5].xyzw
dp4 r1.x, cb1[0].xyzw, r0.xyzw
dp4 r1.z, cb1[2].xyzw, r0.xyzw
mad r0.xyzw, cb0[4].xyzw, r1.xxxx, r2.xyzw
mad r0.xyzw, cb0[6].xyzw, r1.zzzz, r0.xyzw
add o0.xyzw, r0.xyzw, cb0[7].xyzw
mul r0.xyz, v1.xyzx, l(200.000000, 200.000000, 200.000000, 0.000000)
mad o1.xyz, r1.xyzx, l(200.000000, 200.000000, 200.000000, 0.000000), r0.xyzx
ret
// Approximately 12 instruction slots used
当たり前です。これは元の例題が悪かったです。
ただの積和なので畳み込まれてしまいました。
ここまできちんとオプティマイズかかるんですね。
逆に attribute が [loop] (または無指定) だと意味のない演算でも
そのままループに展開されてしまうわけです。
ほんのわずかに複雑なコードにしてみます。
for( int i= 0 ; i< 200 ; i++ ){
Out.Normal+= Temp[i&3];
Out.Normal+= wpos;
}
これでもまだ法則性があるので最適化の余地があります。
[loop] で 20slot、[unroll] で 409slot の命令になります。
速度は2倍差ほど。
[loop] 20 slot 1652 usec [unroll] 409 slot 806 usec
[unroll] だとこんな感じに展開されています。
add r0.xyz, r0.xyzx, cb1[0].xyzx
add r0.xyz, r1.xyzx, r0.xyzx
add r0.xyz, r0.xyzx, cb1[1].xyzx
add r0.xyz, r1.xyzx, r0.xyzx
add r0.xyz, r0.xyzx, cb1[2].xyzx
add r0.xyz, r1.xyzx, r0.xyzx
add r0.xyz, r0.xyzx, cb1[3].xyzx
:
さらに法則性を取り除きます。
for( int i= 0 ; i< 200 ; i++ ){
Out.Normal+= Temp[(int)(Pos.x*i)&3];
Out.Normal+= wpos;
}
これだとおそらく [unroll] でも極端な差が出ないと予想できます。
逆転しました。
[loop] 23 slot 3296 usec [unroll] 564 slot 12786 usec
[unroll] 側の時間増加が極端なので何か他に原因がありそうです。
使用する命令スロット数の増加もペナルティがあるのかもしれません。
ループ回数を変えて計測してみました。
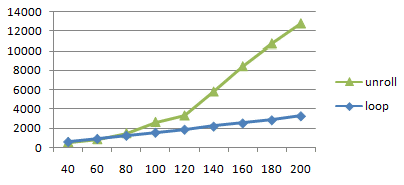
loop u-slot [unroll] l-slot [loop] 40 124 565 23 651 usec 60 179 866 23 967 80 234 1488 23 1284 100 289 2653 23 1600 120 344 3320 23 1915 140 399 5810 23 2232 160 454 8430 23 2558 180 509 10730 23 2882 200 564 12786 23 3296
80 と 120 前後で大きな変化があるようです。slot 数でいえば
234~399のあたりです。
この数値を目安にして別の演算でも同じ傾向が出るか確認してみます。
これも unroll でリニアなコードに展開されます。
Out.Normal= 0;
for( int i= 0 ; i< 100 ; i++ ){
Out.Normal+= pow( i, In.Pos.x );
}
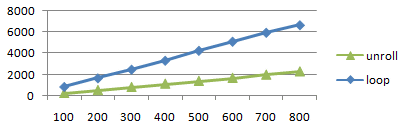
loop u-slot [unroll] [loop] 100 159 252 843 usec 200 309 532 1656 300 458 824 2482 400 609 1130 3323 500 759 1400 4263 600 909 1686 5120 700 1059 1988 5970 800 1209 2290 6678
きれいなリニアです。命令は 1000slot 超えても問題ないし、
しかも unroll の方が速いし、命令スロット数はまったく影響を
与えていないように見えます。
[unroll] で遅くなる先ほどの shader が、unroll すると意外に
temporary register を消費していることがわかりました。
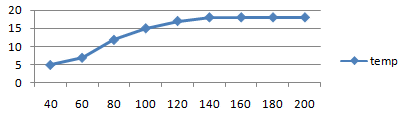
loop slot time temp
[unroll] 40 124 565 5
[unroll] 60 179 866 7
[unroll] 80 234 1488 12
[unroll] 100 289 2653 15
[unroll] 120 344 3320 17
[unroll] 140 399 5810 18
[unroll] 160 454 8430 18
[unroll] 180 509 10730 18
[unroll] 200 564 12786 18
80~120 前後での急激な負荷上昇と一致します。どうやら速度低下の
原因は、セオリー通り temporary register 数だったようです。
単なるループ展開だと思って見落としていました。
結論は、[unroll] の方が高速。だけど最適化によって temp register
が増えてしまうくらいなら素直に [loop] した方がまし。
unroll するけど積極的な最適化をしない attribute もあると
もう少し違ってくる可能性があります。
最適化レベルの /O0~/O3 はとくに変化が見られませんでした。
[unroll] かつ /Od が一番近い結果になりますが、実行すると差が
でません。内部で最適化かかってしまっていたのか、切り替えがうまく
機能していなかったのか、本当に同じ速度だったのか、
まだまだ調べる余地がありそうです。