元の記事エントリ
・Direct3D 10 ShaderModel4.0 ピクセル単位の半透明ソートを行う
少々わかりにくかったかもしれませんので補足します。
実際のシーンのレンダリング時に、フレームバッファの各ピクセル単位で
描画履歴を全部保存しています。実際に書き込まれた色とZ深度、そして
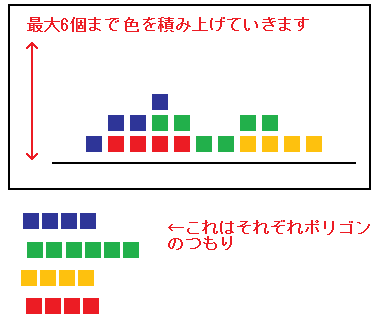
そのピクセルに何回描いたか。
これを浮動少数 float4 ×2~4 に encode して詰め込み、最大 6回分
格納します。
最後に encode された情報を全部 decode して、順番にピクセルごとに
blend しなおすわけです。
これらの処理は各ピクセルごとに独立しています。回数判定もピクセル
単位なので、ポリゴンの重なりや Draw 命令の回数等とは関連しないし
影響を受けることもありません。
またこの処理は Hardware の Blend 機能だけで実現する必要があります。
32bit float には演算によって 8bit ×3個まで値が格納できます。
IEEE754 の単精度の仮数部は 23bit ですが実際は 24bit の情報量が
あるためです。
3回以上値が加算されてしまうと、デコードするときに不要な情報が混ざり
ノイズとなります。Blend 演算だけで必要なピクセルの選択も行わなければ
なりません。
これは浮動少数単精度の制限を使います。3回以上描き込まれたピクセルの
値は仮数部の精度の範囲外に押し込み、必要な値だけ残るようにします。
まとめると
・float に複数の値を正確に畳み込んで、あとから取り出す手段
・Blend 機能だけで値を encode する手段
・Blend 機能だけで履歴(回数)による値の選択と切捨てを行わせる手段
が必要となるわけです。
AlphaToCoverage との違いは次のとおりでしょうか。
・粒状感が出ない
・ブレンドアルゴリズムを任意に持てる (SrcAlpha+InvSrcAlpha 以外も可能)
・最後に Shader でブレンドするので、Hardware Blend 機能より高度な
演算も実装できる
MRT を増やして追加パラメータを格納すれば、ソート後のブレンド時に
ピクセルごとに演算手法の選択もできるかもしれません。
またアルゴリズム的に大変応用が利くので、フレームバッファに情報を
蓄積していく技としてさまざまな手法に活用することができます。
Z剥がしの方法とは違い、シーンのレンダリングは一度で済むのでそこそこの
速度で動作しています。
欠点は
・現在最大6回までしか保持できない
・浮動少数演算の丸め対策で現状 7bit 精度になっている(6 layerのみ)
・保存する分だけメモリと 帯域を かなり 使う
・並べ替えなど、動的分岐の多い重いシェーダーが走る
などなど。