x86 の Atom を搭載した Android Tablet も増えてきました。
本来なら NDK を使用したアプリケーションの互換性が気になるところです。
ところが実際はほとんど問題が起こらず、想像以上にそのまま動作するものが多いようです。
最初から複数のアーキテクチャに対応しているアプリももちろんありますが、
x86 未対応でも動く仕組みが用意されています。
・Bay Trailが実現する、WindowsとAndroidが共存するタブレット
x86 の Android 端末は armeabi-v7a のコードを x86 に変換して実行することができます。
実際に試してみました。
ASUS MeMO Pad 7 ME176 (BayTrail-T Atom Z3745) を使い、
ARMv7A のバイナリ (so) だけ含んだ VFP Benchmark を走らせてみました。
NDK かつ assembler を使ったプログラムながら、きちんと動作していることがわかります。
下記はそれぞれのスクリーンショット。
CPU/FPU の種類も正しく判別している点に注目です。(理由は後述)
↓armeabi-v7a バイナリのみ含む場合

↓x86 バイナリのみ含む場合
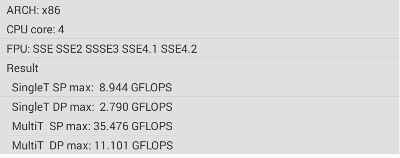
結果のまとめ
Z3745 x86 Z3745 ARM-BT
---------------------------------------------------------
SingleFP Single-thread 8.95 6.14 69%
DoubleFP Single-thread 2.80 1.48 53%
SingleFP MultiT-hread 35.37 24.33 69%
DoubleFP MultiT-tread 11.06 5.91 53%
Matrix 4x4 Single-thread 3.06 1.79 59%
Matrix 4x4 Multi-thread 12.26 7.23 59%
・プロセッサのピーク演算能力
・単位は GFLOPS、数値が大きい方が高速
・ARM-BT = ARM Binary Translation
ARM コードは単精度浮動小数点数命令で x86 の 69%、
倍精度でおよそ 53% の速度となっています。
ただしこれは最善ケースのみです。
Matrix の方が比較的現実的な数値に近いと思われます。
↓他の CPU との比較。
clock SP DP SP-MT DP-MT
-------------------------------------------------------------------
BayTrail Z3745 ARM-BT x4 1.86GHz 6.14 1.48 24.33 5.91 **
BayTrail Z3745 x86 x4 1.86GHz 8.95 2.80 35.37 11.06
BayTrail J1900 x64 x4 2.41GHz 14.48 3.62 57.90 14.47
Atom z540 x1 1.86GHz 8.92 1.81 10.93 1.85
Tegra3 Cortex-A9 x4 1.30GHz 4.78 1.20 18.91 4.72
Tegra4 Cortex-A15 x4 1.80GHz 13.37 2.66 51.35 9.86
Snapdragon S4 Pro Krait x4 1.50GHz 11.95 3.01 47.81 11.75
Snapdragon 800 MSM8974 x4 2.20GHz 17.13 4.29 67.54 16.87
Rockchip RK3066 Cortex-A9 x2 1.60GHz 6.35 1.59 12.66 3.14
MediaTek MT8125 Cortex-A7 x4 1.20GHz 2.37 1.17 9.47 4.65
Apple A5 (iPad2) Cortex-A9 x2 1.00GHz 3.97 0.99 7.83 1.96
Apple A6 (iPad4) Swift x2 1.30GHz 10.86 1.82 21.50 3.57
Apple A7 (5s) Cyclone x2 1.40GHz 20.62 10.31 40.87 20.48
上の表では ARM Binary Translation は同クロックの Cortex-A9 よりも
若干遅い程度、動作クロックの分だけ Cortex-A9 よりも高速な結果となっています。
最近増えてきた低価格帯デバイスの Cortex-A7 Quad core よりは、
ずっと高速に演算できるでしょう。
ただしあくまでピーク演算能力の比較なので、
実アプリケーションに則した結果ではない点に注意してください。
演算命令の分布次第で速度が異なります。
例えば下の命令単位の結果を見ると変換された vmla が特に低速であることがわかります。
vmla を多用した最適化されたプログラムほど速度が遅くなるかもしれません。
上の表は今回の用途では適切なベンチマークではないので、参考程度にお願いします。
// armeabi-v7a (Binary Translation)
* VFP/NEON (単精度 fp) single-thread
sec MFLOPS MFLOPS
----------------------------------------------------------------
VFP fmuls (32bit x1) n8 : 3.954 1011.6 1011.6
VFP fadds (32bit x1) n8 : 3.332 1200.6 1200.6
VFP fmacs (32bit x1) n8 : 8.371 955.7 955.7
VFP vfma.f32 (32bit x1) n8 : - - -
NEON vmul.f32 (32bit x2) n8 : 6.009 1331.4 1331.4
NEON vadd.f32 (32bit x2) n8 : 3.816 2096.6 2096.6
NEON vmla.f32 (32bit x2) n8 : 22.824 701.0 701.0
NEON vfma.f32 (32bit x2) n8 : - - -
NEON vmul.f32 (32bit x4) n8 : 6.012 2661.2 2661.2
NEON vadd.f32 (32bit x4) n8 : 3.347 4780.6 4780.6
NEON vmla.f32 (32bit x4) n8 : 16.516 1937.5 1937.5
NEON vfma.f32 (32bit x4) n8 : - - -
↑ FMA は無く VFPv3-D32 NEON 相当。
// x86
* SSE/AVX (単精度 fp) single-thread
sec MFLOPS MFLOPS
----------------------------------------------------------------
SSE mulss (32bit x1) n8 : 2.203 1816.0 1816.0
SSE addss (32bit x1) n8 : 2.152 1858.6 1858.6
SSE mulps (32bit x4) n8 : 4.292 3728.2 3728.2
SSE addps (32bit x4) n8 : 2.146 7457.2 7457.2
SSE mul+addps (32bit x4) n8 : 2.146 7456.3 7456.3
SSE ml+ad+addps (32bit x4) n6 : 1.877 8949.5 8949.5
SSE mulss (32bit x1) ns4 : 2.145 1864.4 1864.4
SSE addss (32bit x1) ns4 : 2.145 1864.7 1864.7
SSE mulps (32bit x4) ns4 : 4.291 3728.9 3728.9
SSE addps (32bit x4) ns4 : 2.153 7430.9 7430.9
AVX vmulps (32bit x8) n8 : - - -
AVX vaddps (32bit x8) n8 : - - -
AVX vmul+addps (32bit x8) n8 : - - -
AVX vml+ad+adps (32bit x8) n6 : - - -
● ABI
ro.product.cpu.abi=x86 ro.product.cpu.abi2=armeabi-v7a
第二 ABI として armeabi-v7a が指定されています。
同じ ARM でも armeabi (ARMv5TE) は変換対象とならないようです。
実際に armeabi だけのプログラムを走らせましたが実行できませんでした。
armeabi-v7a ではなく armeabi でビルドしている古いプログラムは
動作しないことになります。
対応アプリが 100% にならない理由の一つだと思われます。
● CPU Features
NDK に付属している CPU Features Library は、SSE,NEON 等の CPU 拡張命令が
使えるかどうかを返します。
このライブラリは Hardware Register MVFR (CPUID相当) を見ているのではなく、
基本的には /proc/cpuinfo から判断しています。
そのため lib (so) バイナリを x86 に変換するだけでは互換性が不十分です。
x86 の Binary Translator は ARM コードからアクセスした場合
/proc/cpuinfo も ARM 相当に置き換えているようです。
CPU Feature を正しく認識できているのはこの機能のおかげでしょう。
armeabi-v7a のコードから見える cpuinfo は下記の通りです。
Processor : ARMv7 processor rev 1 (v7l) BogoMIPS : 1500.0 Features : neon vfp swp half thumb fastmult edsp vfpv3 Processor : ARMv7 processor rev 1 (v7l) BogoMIPS : 1500.0 Features : neon vfp swp half thumb fastmult edsp vfpv3