複数台の PC を使って OpenClaw を使用しています。OpenClaw は多くのトークンを消費しますので、クラウドの API を使わずに自分の PC だけで運用できないかいろいろ試しています。
現在は以下の図のように 120b クラスのモデルを使用しています。AI 用の特別なマシンではなく、(メモリ増設した) 汎用の PC です。
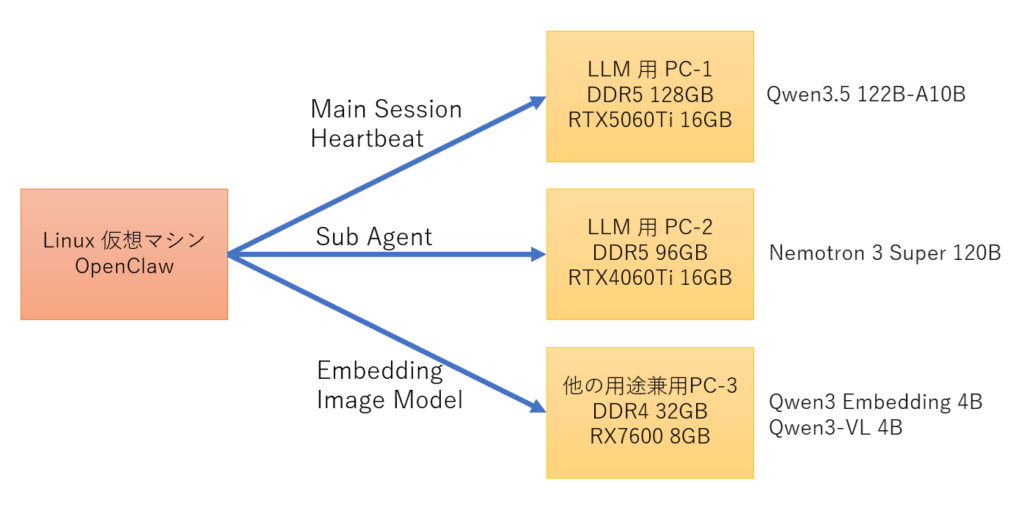
本来なら LLM 用の PC は 1台だけでも動作できるのですが、複数台に分けているのは理由があります。PC-3 は空いてる PC の VRAM を間借りすることが目的です。PC-2 を用意したのは Sub Agent をバックグラウンドで並列動作させられることと、Main セッションの KV キャッシュとの分離のためです。
もし使える PC 台数に余裕があるなら、だいぶ贅沢ですが Heartbeat 用 PC も分けることができます。
一般向け PC での生成速度
前回説明したように、普通の PC でもメモリさえあれば 100b 以上のモデルも動くようになってきました。生成速度は 10~20 token/s ほどなので、AI 専用のマシンやクラウドの API と比べると非常に低速です。
それでも Slack のようにストリーミング表示してくれるクライアントで使っていると、思ったよりもずっと早くレスポンスが返ってくることがわかります。生成速度が遅くても使えているのは KV キャッシュが再利用できているおかげです。
逆にキャッシュが効かないケースでは一度のやりとりでも 5~10分ほど待たされるので、これが非常に重要であることがわかります。
Sub Agent を別の PC に割り当てる
OpenClaw は大きなコンテキストサイズを必要としますが、コンテキストウィンドウ長を増やすとその分生成速度は落ちていきます。VRAM 16GB でバランスを取るとだいたい 64K くらいがちょうどよいかと思います。
OpenClaw はコンパクション後でもトークン数は 20K 以上あり、使っていると簡単に 50K を超えます。そのため Main セッションの場合は、コンテキストウィンドウはほぼ単一のスロットです。この状態で Sub Agent などの別のセッションが走ると KV キャッシュが上書きされてしまい、再び長い再生成 (Prefill) 待ちになってしまうことがあります。
そこで Sub Agent に使う LLM 用の PC を別に用意すれば、長いコンテキストでのキャッシュ領域の衝突を避けることができます。.openclaw/openclaw.json の設定だと以下のようになります。
{
"agents": {
"defaults": {
"model": {
"primary": "llamacpp-pc1/Qwen3.5-122B-A10B" ← Main モデル
},
"subagents": {
"model": "llamacpp-pc2/NVIDIA-Nemotron-3-Super-120B-A12B", ← Sub Agent 用
"maxConcurrent": 1
},
"maxConcurrent": 2,
"timeoutSeconds": 1800,
~
}
},
"models": {
"providers": {
"llamacpp-pc1": {
"api": "openai-completions",
"apiKey": "llama.cpp",
"baseUrl": "http://192.168.0.101:8080/v1", ← Main 用 LLM PC の URL
"models": [
{
"contextWindow": 65536,
"cost": { "cacheRead": 0, "cacheWrite": 0, "input": 0, "output": 0 },
"id": "Qwen3.5-122B-A10B",
"input": [ "text", "image" ],
"maxTokens": 32768,
"name": "Qwen3.5-122B-A10B",
"reasoning": true
}
]
},
"llamacpp-pc2": {
"api": "openai-completions",
"apiKey": "llama.cpp",
"baseUrl": "http://192.168.0.102:8080/v1", ← Sub Agent 用 LLM PC の URL
"models": [
{
"contextWindow": 65536,
"cost": { "cacheRead": 0, "cacheWrite": 0, "input": 0, "output": 0 },
"id": "NVIDIA-Nemotron-3-Super-120B-A12B",
"input": [ "text" ],
"maxTokens": 32768,
"name": "NVIDIA-Nemotron-3-Super-120B-A12B",
"reasoning": true
}
]
}
}
},
~
}また PC を分けたことで、Sub Agent を完全にバックグラウンドで並列に走らせられるようになります。
なお Heartbeat は Main と同じコンテキストを共有しますが、同じスロットが割り当てられるので実行するタスクによっては競合する可能性があります。もし Heartbeat に使う LLM 用 PC も別に用意する場合は以下のように設定します。
{
"agents": {
"defaults": {
"model": {
"primary": "llamacpp-pc1/Qwen3.5-122B-A10B" ← Main モデル
},
"subagents": {
"model": "llamacpp-pc2/NVIDIA-Nemotron-3-Super-120B-A12B", ← Sub Agent 用
"maxConcurrent": 1
},
"heartbeat": {
"model": "llamacpp-pc4/Qwen3.5-122B-A10B" ← Heartbeat 用
},
"maxConcurrent": 2,
"timeoutSeconds": 1800,
~
}
},
~
}注意点
OpenClaw 用に Mac 上で LMStudio を使う場合は GGUF の方をお勧めします。単純な生成速度なら MLX の方が速いのですが、MLX ではキャッシュが再利用されずに毎回 Prefill が走ってしまうようです。
LLM 用 PC 側での実行例
LLM 用 PC では llama.cpp を使っています。以下はその実行例です。
llama-server.exe --model Qwen3.5-122B-A10B-Q4_K_M-00001-of-00002.gguf --mmproj mmproj-Qwen3.5-122B-A10B-BF16.gguf --alias Qwen3.5-122B-A10B -t 16 --ctx-size 65536 --host 0.0.0.0 --port 8080 --temp 0.6 --min-p 0.0 --top-p 0.95 --top-k 20 -fa onllama-server --model NVIDIA-Nemotron-3-Super-120B-A12B-Q4_K_M-00001-of-00003.gguf --alias NVIDIA-Nemotron-3-Super-120B-A12B -t 24 --ctx-size 65536 --temp 0.6 --min-p 0.0 --top-p 0.95 --host 0.0.0.0 --port 8080 -fa on複数の Sub Agent を同時実行するには
subagents.maxConcurrent = 1 を指定していますが、複数の Sub Agent を実行することは可能です。ただし並列度は 1になるので、Agent の数だけ時間がかかることになります。
もし実行時間短縮のために並列に走らせたい場合は、Sub Agent 用に更に追加の PC を割り当てる必要があります。直接コマンドから spawn 起動する場合は個別にモデル指定ができますが、設定ファイルの openclaw.json には Agent 毎に一つの Sub Agent モデルしか記述しておくことができないようです。
複数台の PC を使った並列化を行いたい場合は、個別にコマンドから model 指定で spawn するか、もしくは別の Coding Agent を利用する方法があります。例えば OpenClaw から Codex CLI の呼び出しができるので、Codex 側の設定で別の PC の Local LLM を割り当てておけば以下の 3つで並列実行になります。
- Main Session / Heartbeat
- Sub Agent
- Codex CLI
画像認識モデルの指定
クラウドの商用モデルと違い、Local LLM が使うオープンモデルは画像認識に対応していないことがあります。Qwen3.5 の場合は画像入力に対応しているので不要ですが、他のモデルを使うときは以下のように VLM モデルを指定することができます。ここでは更に別の PC を割り当てています。
{
"agents": {
"defaults": {
"model": {
"primary": "llamacpp-pc1/NVIDIA-Nemotron-3-Super-120B-A12B" ← Main モデル
},
"imageModel": {
"primary": "lmstudio-pc3/qwen/qwen3-vl-4b" ← 画像認識 用
},
"subagents": {
"model": "llamacpp-pc2/NVIDIA-Nemotron-3-Super-120B-A12B", ← Sub Agent 用
"maxConcurrent": 1
},
"maxConcurrent": 2,
"timeoutSeconds": 1800,
~
}
},
"models": {
"providers": {
~ pc1/pc2 省略
"lmstudio-pc3": {
"api": "openai-completions",
"apiKey": "lmstudio",
"baseUrl": "http://192.168.0.103:1234/v1", ← 画像認識 用 VLM PC の URL
"models": [
{
"contextWindow": 16384,
"cost": { "cacheRead": 0, "cacheWrite": 0, "input": 0, "output": 0 },
"id": "qwen/qwen3-vl-4b",
"input": [ "text", "image" ],
"maxTokens": 16384,
"name": "qwen/qwen3-vl-4b",
"reasoning": true
}
]
},
}
},
~
}テキスト埋め込みモデルの指定
OpenClaw で Local LLM を使う場合は、メモリ検索用の埋め込みモデルを指定する必要があります。
OpenClaw が走っている PC のスペックが高く、RAM もストレージも余裕がある場合は CPU が使えます。とはいえ 300m (0.3b) でも 1GB ほどメモリを消費しますので、スペックに余裕がない場合はこれまでと同じ様に他の PC を割り当てて使うことが可能です。
Ollama で Local CPU を使う場合の例
- Ollama をインストール
- モデルをダウンロード
- ollama pull embeddinggemma:300m
- 以下の設定を追加
{
"agents": {
"memorySearch": {
"provider": "openai",
"model": "embeddinggemma:300m", ← 埋め込みモデル
"fallback": "none",
"remote": {
"baseUrl": "http://127.0.0.1:11434/v1", ← 埋め込みモデル用 PC の URL
"apiKey": "ollama"
}
},
~
}
},
~
}他の PC で処理する場合の例
LMStudio を使って他の PC 上で走らせる場合の設定例。
{
"agents": {
"memorySearch": {
"provider": "openai",
"model": "text-embedding-qwen3_embedding_4b", ← 埋め込みモデル
"fallback": "none",
"remote": {
"baseUrl": "http://192.168.2.103:11434/v1", ← 埋め込みモデル用 PC の URL
"apiKey": "lmstudio"
}
},
~
}
},
~
}上記以外に provider = “local” を使う方法もあります。以下のページにまとめています。
しばらく使用してみて
llama.cpp のキャッシュ再利用のおかげで思ったよりもレスポンスは早いです。Slack で簡単な応答なら、リアクションマークが付いたあと 10秒くらいでストリーミングが始まります。ストリーミング表示されないクライアントだと全部生成してからメッセージが届くため、体感速度はだいぶ下がると思います。
たまに Heartbeat ジョブが走って Prefill 待ちが入ることがありますが、それでも長くて 2分くらいです。Heartbeat 用 PC があればこの待ち時間がなくなります。
内容も普通にチャットしている分には全く違和感なく、簡単なプログラムの作成なども問題なくこなします。memory も増えて徐々に育てていくことができます。普通に使う分には十分です。700b などの、よりパラメータ数の多いモデルと比べると細かいところでは正確性(追従性)に差が出るようです。メモリ更新などは指示して明示的にやらせた方が良いです。バックアップはこまめに取りましょう。
応答の仕方はモデルによって結構変わります。用途に合わせてモデルや量子化、temperature 等のパラメータ調整をしていくと良いのかもしれません。Sub Agent も当初はタイトル通り Qwen3.5 122B-A10B を使っていたのですが、今は Nemotron 3 Super に置き換えてテストしています。
注意点
OpenClaw で Local LLM を使用する場合はリスクを伴います。必ず完全に隔離した仮想マシンで Sandbox を有効にしてください。また重要な情報は絶対に与えず、テストする場合でもネットワークアクセスを制限しておくことをお勧めします。
{
"agents": {
"defaults": {
"sandbox": {
"mode": "all"
},
~
}
},
~
}openclaw status コマンドを実行すると、制限無しに 300b 未満のモデルを使っている場合にセキュリティの警告が表示されます。今回の説明でも 120b のモデルを使っているためセキュリティ警告が出ています。考えられるリスクとして、AI が騙されて危険な指示に従ってしまう可能性があります。OpenClaw ではできるだけ性能が高いモデルの利用が推奨されていますので、Local LLM を使う場合はご注意ください。