Oculus Quest 2 を入手しました。性能が上がりつつ価格も下がっており、今 VR を始めるなら間違いなくこれが候補にあがるのではないかと思います。ケーブルも外部センサーも不要なモバイル VR でありながらルームスケールに対応しており、Oculus Link を使えば PC の VR ゲームもプレイできます。
Oculus Quest 1 とスペックを比較してみます。
| Oculus Quest | Oculus Quest 2 | |
|---|---|---|
| SoC | Snapdragon 835 | Snapdragon XR2 |
| CPU | Kryo 280 (A73 + A53) | Kryo 585 (A77 + A55) |
| CPU Clock | 2.5GHz / 1.9GHz | 2.8GHz / 2.4GHz / 1.8GHz |
| RAM | 4GB | 6GB |
| GPU | Adreno 540 | Adreno 650 |
| OS | Adnroid 7.1 (API 25) | Android 10 (API 29) |
| Display | OLED 1440 x 1600 x2 | LCD 1832 x 1920 x2 |
| IPD調節 | 無段階 | 3段階のみ |
| 発売 | 2019/05 | 2020/10 |
| 価格 | 49800円 (64GB) | 37100円 (64GB) |
VR HMD はハイエンド向けとモバイル向けに分かれています。ハイエンド向けではトラッキングの精度やトラッカーの数でまだまだ Lighthouse 方式が優勢でしょう。モバイル向けでは仕様的に Oculus Quest で完成されており、Quest 2 はさらなる機能強化が図られています。
まずパネル解像度が上がっており、片目だけで Full HD の 1.7倍 (1920×1832) に達しています。Quest 1 と比べても明らかにドットの隙間が見えにくくなっているのがわかります。
| HMD | ROM | 価格 | 重さ | RAM | 画面 | 解像度比 | |
|---|---|---|---|---|---|---|---|
| Oculus Go | 32GB | 23800円 | $199 | 468g | 3GB | 2560×1440 | 1.00 |
| Oculus Go | 64GB | 29800円 | $249 | 468g | 3GB | 2560×1440 | 1.00 |
| Oculus Quest | 64GB | 49800円 | $399 | 571g | 4GB | 2880×1600 | 1.25 |
| Oculus Quest | 128GB | 62800円 | $499 | 571g | 4GB | 2880×1600 | 1.25 |
| Oculus Quest2 | 64GB | 37100円 | $299 | 503g | 6GB | 3664×1920 | 1.91 |
| Oculus Quest2 | 256GB | 49200円 | $399 | 503g | 6GB | 3664×1920 | 1.91 |
ガーディアンの外に出ると外部カメラの画像に切り替わりますが、Quest 2 の方が歪みが減って明るくなっており、そのまま違和感なく歩けます。
プロセッサも強化されています。スペックを調べると CPU は 1+3+4 構成の Octa core で、それぞれ 2.8GHz, 2.4GHz, 1.8GHz でした。GPU も Adreno 650 だったので、Snapdragon XR2 は Snapdrago 865 をベースにしていると思われます。
基本性能が強化された反面、コストダウンが見える部分もあります。Oculus Go と同じゴムバンドになっており、軽量化されているものの装着時の安定度は Quest 1 の方が上です。また小型化のためか内部の空間に余裕がなくなり、スペーサーを入れてもメガネがかなり入りづらくなっています。
一番残念だったのが、画面を見ながら IPD の微調整ができなくなっていることです。一旦 HMD を外してから直接レンズ部分をずらす必要があり、切り替えも 3段階のみとなっています。
また新しく Oculus デバイスをセットアップする場合は Facebook アカウントが必要です。
● Bluetooth Keyboard
Oculus Quest の UI は更新されており、外部ツールを使わなくても設定から Bluetooth Keyboard をペアリングできるようになっています。Quest 1 でもできるようになっています。
・設定 → テスト機能 → Bluetooth ペアリング
ただしキーボードレイアウトの変更はできないので、日本語配列などレイアウトを切り替えたい場合はやはり TVLauncerGo などの外部ツールから Android 本来の設定画面を呼び出す必要があります。レイアウト変更手順は下記の通り。
・TVLauncerGo → 設定 → システム → 言語と入力 → 物理キーボード → 物理キーボードを選択 → キーボードレイアウトの設定
● TVLauncherGo の呼び出し
Oculus Quest 1 と同じように TVLauncherGo が動きました。アカウントを開発者登録してから PC と USB で接続し、adb コマンドでインストールしています。
・Oculus Go で一般 Android アプリを起動できるランチャーを作ってみた
・GitHub: TVLauncherGo
Oculus TV がシステムに統合されているため、以前の解説と起動方法は異なっています。
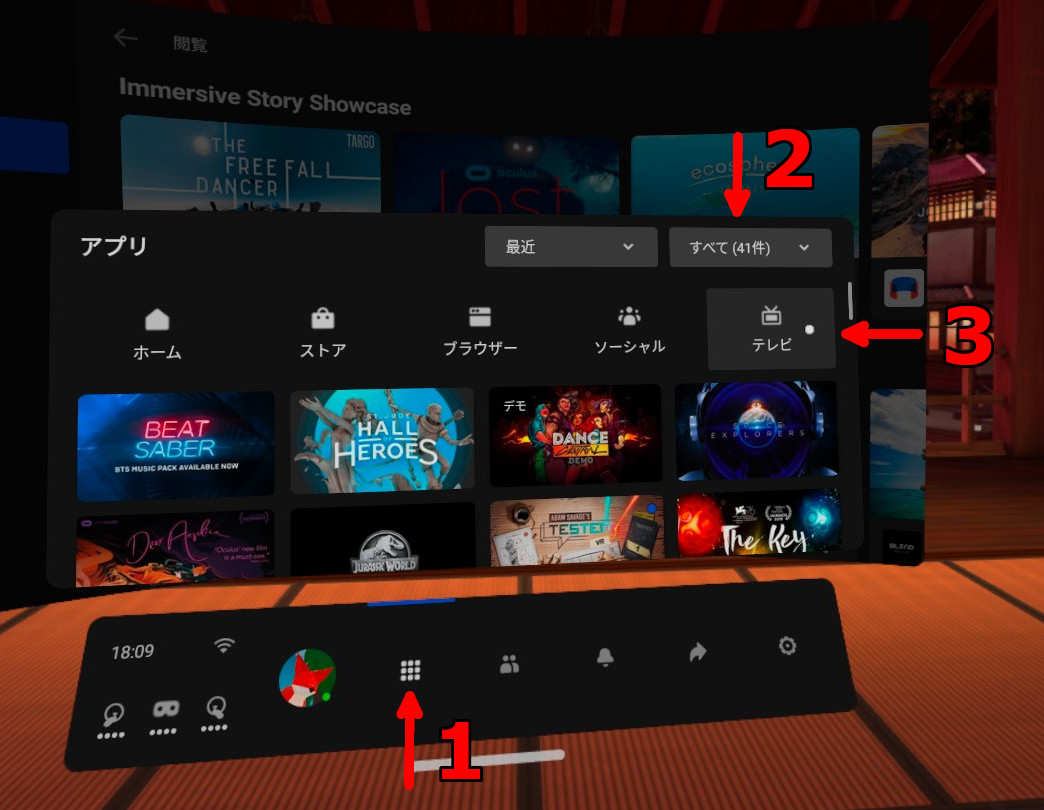
1. Oculus ボタンのメニューから「アプリ」を選択
2. 右上のプルダウンを「すべて」にする
3. 右上の「テレビ」を選択
4. テレビアプリの左から「チャンネル」→「提供元不明のアプリ」

もしくは下記の方法でも直接呼び出せます。
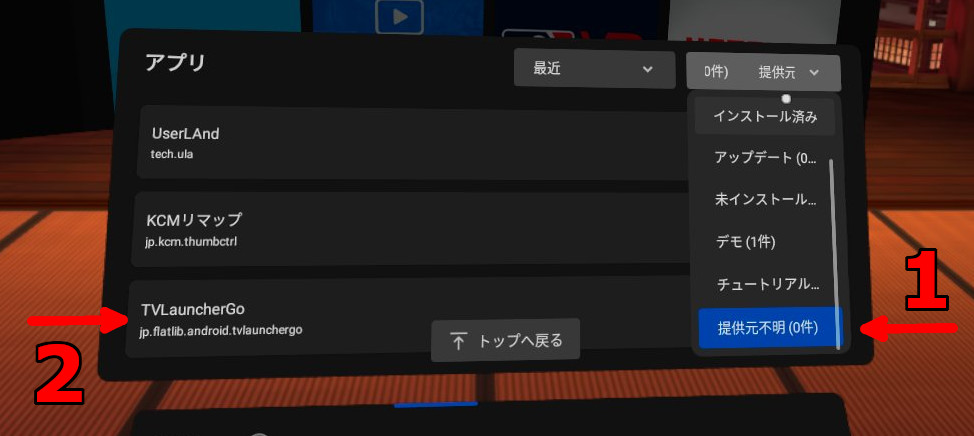
1. アプリの右上のプルダウンを「提供元不明」にする
2. 直接 TV Launcher Go を選ぶ。
● Termux / UserLAnd
Termux は Version によっては動かないことがあるようです。昨年 2020/10 月に試したときは、Quest 1 で使っていた古いバージョンを使用しました。
UserLAnd は問題なくインストールできました。VNC を使うときに注意が必要な点も Quest 1 と同じです。Termux は単独で起動できますが、UserLAnd は TVLauncherGo 経由で呼び出す必要があります。詳しくは下記をご覧ください。
なお Android 10 になったため CTRL+SPACE の入力ができなくなっています。Quest 1 は Android 7.1 なので入力できました。
・UserLAnd : Android 9.0 で Ctrl + SPACE を使えるようにする
関連エントリ
・Oculus Quest で Rift のゲームをプレイする (Oculus Link)
・Oculus Quest 5万円ちょうどで買えるフルスペック VR
・Oculus Quest も文章書き&開発マシンにする
・Android/Oculus Go/Daydream の画面をミラーリングするツールを作ってみた
・Oculus Go で一般 Android アプリを起動できるランチャーを作ってみた
・VR で物が大きく見えたり小さく見えたりするわけ
・Oculus Go は VR ができる新しい携帯ゲーム機