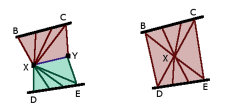
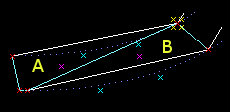
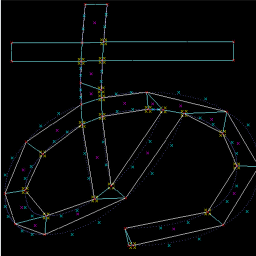
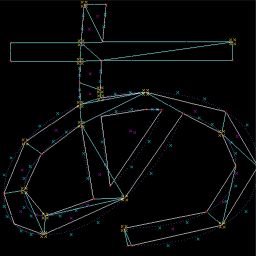
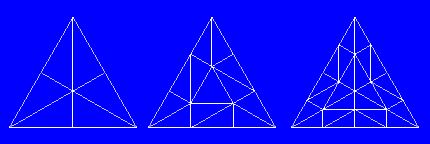
結局 GeometryShader だけで描画できました。
これだと D3D11 でもハードウエアアクセラレートかかるので
回転アニメーションとかも余裕。

入力頂点は、最後の1つを複製して 6頂点単位に変更。
それぞれが float2 × 4 なのは変わらず。
・エッジ x4
・中心座標
・ダミー
描画 TOPOLOGY は D3D11_PRIMITIVE_TOPOLOGY_TRIANGLELIST_ADJ に変更。
これを triangleadj で受け取れば 6 頂点入力ができます。
HS/DS を NULL にして代わりに GS を設定するだけ。
iContext->RSSetState( iRS_WIREFRAME ); UINT stride= sizeof(float)*2*4; UINT offset= 0; iContext->IASetVertexBuffers( 0, 1, &iVBuffer, &stride, &offset ); iContext->IASetInputLayout( iLayout ); iContext->VSSetShader( iVS, NULL, 0 ); iContext->GSSetConstantBuffers( 0, 1, &iBufferV ); iContext->GSSetShader( iGS, NULL, 0 ); iContext->PSSetShader( iPS, NULL, 0 ); iContext->OMSetRenderTargets( 1, &iRenderTargetView, iDepthStencilView ); iContext->IASetPrimitiveTopology( D3D11_PRIMITIVE_TOPOLOGY_TRIANGLELIST_ADJ ); iContext->Draw( vdata0_size*sizeof(float)/(sizeof(float)*2*4), 0 );
各エッジを最大 8 分割と仮定すると最大
8 triangle × 3 × 4edge = 96 頂点出力される可能性があります。
各シェーダーを vs_4_0 gs_4_0 ps_4_0 向けにコンパイルすると
RADEON HD4850 で HARDWARE 動作しました。API は D3D11 のまま。
// gs_4_0
struct VS_OUTPUT {
float2 vPos0 : VSPOS0;
float2 vC0 : VSPOS1;
float2 vC1 : VSPOS2;
float2 vPos1 : VSPOS3;
};
cbuffer pf {
float4x4 WVP;
};
struct DS_OUTPUT {
float4 vPos : SV_Position;
};
void addv( float2 pos, inout TriangleStream stream )
{
DS_OUTPUT dout;
dout.vPos= mul( float4( pos.xy, 0, 1 ), WVP );
stream.Append( dout );
}
float2 UVtoPositionB( const VS_OUTPUT p, float t )
{
float t2= 1.0-t;
float4 u= float4( t2*t2*t2, t2*t2* t*3, t2* t* t*3, t* t* t );
return u.x*p.vPos0.xy +u.y*p.vC0.xy +u.z*p.vC1.xy +u.w*p.vPos1.xy;
}
void Curve4( float2 center, const VS_OUTPUT v,
inout TriangleStream stream )
{
const int step= 8; // = TessFactor
float t= 0;
float tstep= 1.0/step;
float2 prevpos= UVtoPositionB( v, 0 );
for( int i= 0 ; i< step ; i++ ){
t+= tstep;
float2 pos= UVtoPositionB( v, t );
addv( prevpos, stream );
addv( pos, stream );
addv( center, stream );
stream.RestartStrip();
prevpos= pos;
}
}
void Edge( float2 center, const VS_OUTPUT v,
inout TriangleStream stream )
{
if( v.vC0.x > -1e4 ){
Curve4( center, v, stream );
}else{
// 直線の場合
addv( v.vPos0, stream );
addv( v.vPos1, stream );
addv( center, stream );
stream.RestartStrip();
}
}
// step(8) x 3 x 4 = 96
[maxvertexcount(96)]
void main(
triangleadj VS_OUTPUT input[6],
inout TriangleStream stream )
{
Edge( input[4].vPos0, input[0], stream );
Edge( input[4].vPos0, input[1], stream );
Edge( input[4].vPos0, input[2], stream );
Edge( input[4].vPos0, input[3], stream );
}
最適化していないので、四隅と中心の頂点の計算が重複したままです。
関連エントリ
・Direct3D11/DirectX11 (15) GPU を使ったアウトラインフォントの描画の(3)
・Direct3D11/DirectX11 (14) GPU を使ったアウトラインフォントの描画の(2)
・Direct3D11/DirectX11 (13) TessFactor とシェーダーリンクの補足など
・Direct3D11/DirectX11 (12) テセレータのレンダーステート他
・Direct3D11/DirectX11 (11) 互換性とシェーダーの対応表など
・Direct3D11/DirectX11 (10) テセレータの補間
・Direct3D11/DirectX11 (9) テセレータによるアウトラインフォントの描画など
・Direct3D11/DirectX11 (8) テセレータの動作
・Direct3D11/DirectX11 (7) テセレータの流れの基本部分