W-ZERO3/EM・ONE 用ソフト、ctrlswapmini や em1key の
・既知の不具合
・報告をいただいた不具合情報
・現在寄せられている要望
等を登録した BTS を公開しました。現在試験運用です。
閲覧だけなら「ゲストログイン」ボタンで入ることができます。
月別アーカイブ: 2007年8月
Microsoft Gamefest Japan 2007
Shader.jp さんからの情報ですが
・ゲーム開発者のための技術説明会 「Gamefest Japan 2007」 開催
CEDEC から Meltdown が消えたなと思っていたら、独自に
Gamefest Japan を行うみたいですね。
二日間にわたって開催されて結構内容も幅広いようです。
9月は忙しくなりそうです。
・ゲーム開発のための技術説明会 Gamefest Japan 2007 開催 ゲーム制作技術情報を日本で初めて広く一般へ公開
こちらにも書いてあるように Gamefest はもともと開発者限定の
クローズドなイベントだったので、それが広く一般に公開された形です。
ターゲットはやはり開発者で、マルチプラットフォーム化等の推進が
狙いとのことです。
そういえばゲームは、Wii/DS 等ユーザー層の拡大がここ最近のテーマでした。
もしかしたら MS は XNA 関連を中心にして、ユーザーだけでなく
開発の一般への浸透化や、開発者の層の拡大もある程度視野に入れて
いるのかもしれません。
Direct3D 10 GeForce8800GTX は GTS の 1.5倍速い
前々回
・Direct3D 10 Shader4.0 ループと最適化
で行ったテストを、GeForce8800GTX でも試してみました。
テストしたのは、逆転して [loop] の方が高速になる 3番目の
shader です。GeForce8800GTX の傾向は GTS とまったく同じで、
loop 120 回以上で速度低下が顕著になります。
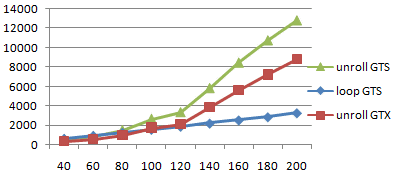
・縦軸は実行にかかった時間(usec)。位置が低い方が高速。
・横軸はループ回数
GeForce8800GTX
loop回数 time GTS比
40 371 1.52
60 570 1.52
80 962 1.55
100 1752 1.51
120 2120 1.57
140 3870 1.50
160 5620 1.50
180 7200 1.49
200 8780 1.45
このデータを見る限り、temporary register の割り当てに関しては
特に GTS と GTX で差がないように見えます。つまりシェーダー
ユニットに対する、割り当て可能な register pool の割合はおそらく
同率になっているのでしょう。
GTS はシェーダーユニット数が少ないけれど、その分潤沢にレジスタを
使えるわけではありませんでした。
数値を取っていて気になったのは、思った以上に GTX が速いという
ことです。上のグラフには前々回の GTS の結果も重ねており、また
表には GTS 比でどれくらい速いのかも書き込んでみました。
だいたい 1.5倍程度 GTX の方が高速に動作している計算です。
こんなに差があったかな・・と思ってスペックを確認してみました。
stream processor shader clock memory clock mem-bus
GeForce8800Ultra 128sp 1500MHz 1080MHz 384bit
GeForce8800GTX 128sp 1350MHz 900MHz 384bit
GeForce8800GTS 96sp 1200MHz 800MHz 320bit
Stream Processor の数で 約1.33 倍
Shader Clock の差で 1.125 倍
1.33 × 1.125 ≒ 1.50
ぴったり計算どおりでした。
シェーダーの実行速度に対して、メモリ速度は clock で 1.125倍、
bus 幅で 1.2倍、あわせて 1.35 倍です。
シェーダーの演算ではなくメモリが足を引っ張る状況では、GTS と
GTX の速度差はもっと小さくなります。
普段体感している速度差は、おそらくこちらの方が近いのではない
でしょうか。
例えば前回(昨日)
・Direct3D 10 Shader4.0 補間レジスタ数と速度の関係
のグラフをもう一度じっくり見てみます。
出力数が 11以上の右側では、GTS と GTX の差を計算してみると
ちょうど 1.5倍前後になっていることがわかります。
ここは上と同じで計算どおりなので、純粋にシェーダーの演算能力
で頭打ちになっているといえるでしょう。
それに比べて左側、11未満の結果では、GTS と GTX の差がほとんど
ありません。GTX の速度は GTS 比でわずか 1.06~1.1 倍程度です。
ほぼこれは Core や Shader、Memory 等の Clock 比 1.125倍に相当
すると考えられます。
つまりここでのボトルネックは、core か Shader Unit 内部に存在
する固定ユニットの実行速度なのでしょう。GTS でも GTX でも GPU
内にたぶん同一個数実装されていると推測できます。
もし仮にこれが 1.35倍に開いていたら、それはおそらくメモリが
足を引っ張っている部分です。
これらの結果から GTX は GTS と比較して、状況によって
1.125~1.5 倍高速に実行できます。メモリ速度を考えると、本当に
1.5倍の速度差がでるようなケースはそれほど多くないと思います。
また同じように GeForce8800Ultra で計算すると、GTS 比で次のよう
になります。
Shader 1.66倍
Memory 1.62倍
Clock 1.224~1.35
これは速いですね。メモリ速度も Shader 並みの比率を保っているので、
比較的1.6倍に近いスループットが期待できそうです。
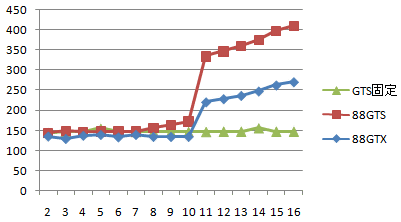
Direct3D 10 Shader4.0 補間レジスタ数と速度の関係
コードを書いていて気になったので少々実験してみました。
VertexShader または GeometryShader が出力する値はラスタライザ
(RasterizerStage) に渡ります。
PixelShader は各ピクセルごとに補間された値を受け取ります。
この VertexShader の出力数値の数と描画速度の関係を調べてみました。
ここでは GeometryShader は NULL にしています。
横軸がシェーダーで使用した出力レジスタの総数、
縦がかかった時間(usec)です。
出力数 命令数 88GTS 88GTX 2 12 145 136 usec 3 13 150 130 4 15 147 138 5 16 148 140 6 17 148 134 7 18 148 140 8 19 157 135 9 20 164 135 10 21 173 135 11 22 335 221 12 23 347 229 13 24 360 237 14 25 376 248 15 26 398 263 16 27 410 271
・88GTS = GeForce8800GTS 640 の結果
・88GTX = GeForce8800GTX の結果
・GTS固定 = GeForce8800GTS で、出力レジスタ数を2個固定にし、
命令数だけ増やしていったもの。
88GTS で出力レジスタ数が2~7個の間特に変化がないのは、動作時間へ
与える影響が他の実行ボトルネックに隠れてしまったためと考えられます。
7~10 までの緩やかな上昇がそれ以前も継続していた可能性が高いです。
その緩やかな上昇の要因として、出力レジスタ数の増加だけではなく
実行する命令数そのものが増えたことも考慮しなければなりません。
そのため出力レジスタ数を2個固定にして、プログラムの長さ(slot数)
を 12~27 まで変化させて同じように速度を量ってみました。
それがグラフ中の「GTS固定」です。
これを見るとほぼ一定なので、やはり10個以前でも出力レジスタ数が
動作に何らかの影響を与えている可能性があります。
注目すべきところはやっぱり出力数 10を超えたところで生じる急激な
変化です。ハード的なバッファの限界、同時に実行可能な補間ユニット
の数、内部バス転送能力の限界、等が考えられます。
VertexShader そのものの命令数が増加して実行時間が長くなれば、
それだけ Rasterizer にも余裕ができます。当初は、その拮抗点が
ちょうど10個目の位置にあったのではないかと仮定しました。
だけど「GTS固定」の結果を見ると、この程度の命令数ではほとんど
実行に影響を与えていないことがわかります。
よって 10 はハード的なマジックナンバーである可能性が高いです。
なお、あとから GeForce8800GTX でも同等のテストを行ってみましたが、
10個を越えた時点で発生する大きな変化は一緒でした。
(グラフに加えました)
ShaderModel 毎に対応している補間レジスタ数は次のとおりです。
ShaderModel2.0
・clmap された COLOR0~1 (2個)
・TEXCOORD0~7 (8個)
・POSITION、FOG
ShaderModel3.0
・自由に割り振れる 12個 (o0~11)
ShaderModel4.0
・自由に割り振れる 16個 (o0~o15)
ShaderModel 2.0~3.0 では、たぶんほとんどのケースで出力レジスタ
数は 10個以内に収まってしまうでしょう。
GeForce68/78 など 3.0 当時の設計でも、仕様上の上限よりは若干低い
位置にハードウエア的な制限があったと考えられます。
GeForce8800 で従来のシェーダーも非常に高速なのは、もしかしたら
こんなところにも原因があるのかもしれません。
今回のテストの結論は、もし速度を追求するなら出力レジスタ数は
10個以内に収めましょう、ということです。
ただ、これはあくまでボトルネックになる得る条件の1つに過ぎないので、
通常はピクセル面積ももっと大きいし、VertexShader も長くなるしと
他の実行サイクルの影に隠れてあまり表に出てこない可能性があります。
相殺されている分には実質的な負荷ではないので、高速化を考える場合
はこのあたりのさじ加減が難しいですね。
Direct3D 10 Shader4.0 ループと最適化
Direct3D 10 の Shader4.0 は、実行可能な命令スロットも多いし
整数型も整数演算も扱えるし、HLSL を使うと Shader であることを
忘れそうになります。
条件分岐やループ命令等もそのまま記述し、当たり前のように実行
できるようになりました。
例えばまったく意味のない内容ですが、VertexShader の最後に
わざとこんなコードを書いてみます。
Out.Normal= 0;
for( int i= 0 ; i< 200 ; i++ ){
Out.Normal+= In.Normal;
Out.Normal+= wpos;
}
描画するデータは次のとおり。
・Teapot (Maxのプリミティブ)
・ポリゴン数 57600
・頂点数 29646
Pixel の影響をできるだけ受けないように、PixelShader は固定の
定数を return するだけとし、描画面積も点に近い状態でテストします。
実行するとさすがに時間がかかって、GPU 時間で 1410 usec ほど
消費しました。(GeForce8800GTS 640)
コンパイルされたコードはこんな感じです。命令コードに loop 命令が
あって、本当に Shader 内でループ実行されていることがわかります。
vs_4_0
dcl_input v0.xyz
dcl_input v1.xyz
dcl_output_siv o0.xyzw , position
dcl_output o1.xyz
dcl_constantbuffer cb0[8], immediateIndexed
dcl_constantbuffer cb1[3], immediateIndexed
dcl_temps 3
mov r0.xyz, v0.xyzx
mov r0.w, l(1.000000)
dp4 r1.x, cb1[0].xyzw, r0.xyzw
dp4 r1.y, cb1[1].xyzw, r0.xyzw
dp4 r1.z, cb1[2].xyzw, r0.xyzw
mul r0.xyzw, r1.yyyy, cb0[5].xyzw
mad r0.xyzw, cb0[4].xyzw, r1.xxxx, r0.xyzw
mad r0.xyzw, cb0[6].xyzw, r1.zzzz, r0.xyzw
add o0.xyzw, r0.xyzw, cb0[7].xyzw
mov r0.xyzw, l(0,0,0,0)
loop
ige r1.w, r0.w, l(200)
breakc_nz r1.w
add r2.xyz, r0.xyzx, v1.xyzx
add r0.xyz, r1.xyzx, r2.xyzx
iadd r0.w, r0.w, l(1)
endloop
mov o1.xyz, r0.xyzx
ret
// Approximately 19 instruction slots used
元のソースコードに loop 展開のアトリビュートを次のように追加すると
Out.Normal= 0;
[unroll] // attribute
for( int i= 0 ; i< 200 ; i++ ){
Out.Normal+= In.Normal;
Out.Normal+= wpos;
}
145 usec と実行時間が一気に 1/10 になりました。
出力コードを見てみると・・
vs_4_0
dcl_input v0.xyz
dcl_input v1.xyz
dcl_output_siv o0.xyzw , position
dcl_output o1.xyz
dcl_constantbuffer cb0[8], immediateIndexed
dcl_constantbuffer cb1[3], immediateIndexed
dcl_temps 3
mov r0.xyz, v0.xyzx
mov r0.w, l(1.000000)
dp4 r1.y, cb1[1].xyzw, r0.xyzw
mul r2.xyzw, r1.yyyy, cb0[5].xyzw
dp4 r1.x, cb1[0].xyzw, r0.xyzw
dp4 r1.z, cb1[2].xyzw, r0.xyzw
mad r0.xyzw, cb0[4].xyzw, r1.xxxx, r2.xyzw
mad r0.xyzw, cb0[6].xyzw, r1.zzzz, r0.xyzw
add o0.xyzw, r0.xyzw, cb0[7].xyzw
mul r0.xyz, v1.xyzx, l(200.000000, 200.000000, 200.000000, 0.000000)
mad o1.xyz, r1.xyzx, l(200.000000, 200.000000, 200.000000, 0.000000), r0.xyzx
ret
// Approximately 12 instruction slots used
当たり前です。これは元の例題が悪かったです。
ただの積和なので畳み込まれてしまいました。
ここまできちんとオプティマイズかかるんですね。
逆に attribute が [loop] (または無指定) だと意味のない演算でも
そのままループに展開されてしまうわけです。
ほんのわずかに複雑なコードにしてみます。
for( int i= 0 ; i< 200 ; i++ ){
Out.Normal+= Temp[i&3];
Out.Normal+= wpos;
}
これでもまだ法則性があるので最適化の余地があります。
[loop] で 20slot、[unroll] で 409slot の命令になります。
速度は2倍差ほど。
[loop] 20 slot 1652 usec [unroll] 409 slot 806 usec
[unroll] だとこんな感じに展開されています。
add r0.xyz, r0.xyzx, cb1[0].xyzx
add r0.xyz, r1.xyzx, r0.xyzx
add r0.xyz, r0.xyzx, cb1[1].xyzx
add r0.xyz, r1.xyzx, r0.xyzx
add r0.xyz, r0.xyzx, cb1[2].xyzx
add r0.xyz, r1.xyzx, r0.xyzx
add r0.xyz, r0.xyzx, cb1[3].xyzx
:
さらに法則性を取り除きます。
for( int i= 0 ; i< 200 ; i++ ){
Out.Normal+= Temp[(int)(Pos.x*i)&3];
Out.Normal+= wpos;
}
これだとおそらく [unroll] でも極端な差が出ないと予想できます。
逆転しました。
[loop] 23 slot 3296 usec [unroll] 564 slot 12786 usec
[unroll] 側の時間増加が極端なので何か他に原因がありそうです。
使用する命令スロット数の増加もペナルティがあるのかもしれません。
ループ回数を変えて計測してみました。
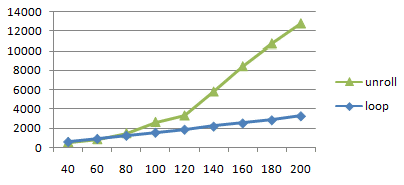
loop u-slot [unroll] l-slot [loop] 40 124 565 23 651 usec 60 179 866 23 967 80 234 1488 23 1284 100 289 2653 23 1600 120 344 3320 23 1915 140 399 5810 23 2232 160 454 8430 23 2558 180 509 10730 23 2882 200 564 12786 23 3296
80 と 120 前後で大きな変化があるようです。slot 数でいえば
234~399のあたりです。
この数値を目安にして別の演算でも同じ傾向が出るか確認してみます。
これも unroll でリニアなコードに展開されます。
Out.Normal= 0;
for( int i= 0 ; i< 100 ; i++ ){
Out.Normal+= pow( i, In.Pos.x );
}
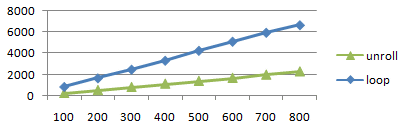
loop u-slot [unroll] [loop] 100 159 252 843 usec 200 309 532 1656 300 458 824 2482 400 609 1130 3323 500 759 1400 4263 600 909 1686 5120 700 1059 1988 5970 800 1209 2290 6678
きれいなリニアです。命令は 1000slot 超えても問題ないし、
しかも unroll の方が速いし、命令スロット数はまったく影響を
与えていないように見えます。
[unroll] で遅くなる先ほどの shader が、unroll すると意外に
temporary register を消費していることがわかりました。
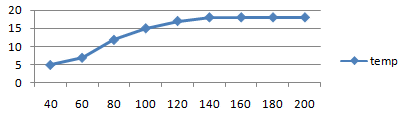
loop slot time temp
[unroll] 40 124 565 5
[unroll] 60 179 866 7
[unroll] 80 234 1488 12
[unroll] 100 289 2653 15
[unroll] 120 344 3320 17
[unroll] 140 399 5810 18
[unroll] 160 454 8430 18
[unroll] 180 509 10730 18
[unroll] 200 564 12786 18
80~120 前後での急激な負荷上昇と一致します。どうやら速度低下の
原因は、セオリー通り temporary register 数だったようです。
単なるループ展開だと思って見落としていました。
結論は、[unroll] の方が高速。だけど最適化によって temp register
が増えてしまうくらいなら素直に [loop] した方がまし。
unroll するけど積極的な最適化をしない attribute もあると
もう少し違ってくる可能性があります。
最適化レベルの /O0~/O3 はとくに変化が見られませんでした。
[unroll] かつ /Od が一番近い結果になりますが、実行すると差が
でません。内部で最適化かかってしまっていたのか、切り替えがうまく
機能していなかったのか、本当に同じ速度だったのか、
まだまだ調べる余地がありそうです。