Oculus Go にも Bluetooth Keyboard が接続できて、さらに一般の Android アプリが動くらしいと今更ながら知ったので、先人の知恵をお借りしつつ UserLAnd を動かしてみました。どこでも Oculus Go をかぶって大画面で日本語文章書いたりプログラム書いたりできます。
Remote Desktop ではないので Network がなくても単体で使えます。
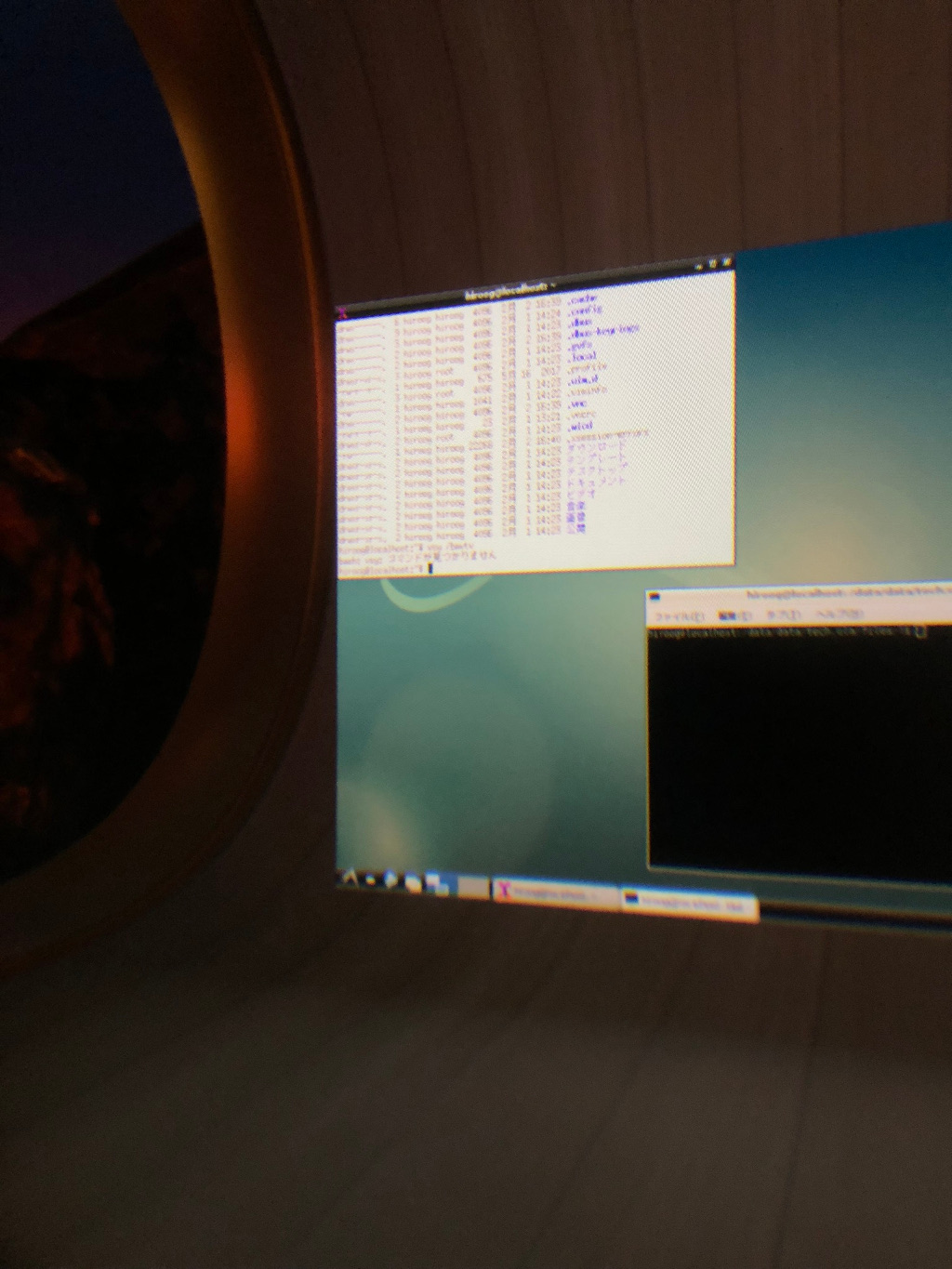

↑ Oculus Go で動く Debian の Desktop。Oculus TV は残念ながら画面キャプチャできないので、Oculus Go を覗いたところを無理やり写真に撮っています。
参考にさせていただいた情報
・Oculus Go Tips
・KILINBOX: Oculus GoでAndroidアプリを動かす
調べてみたらすでに同じようなことを実践している方もいらっしゃるようです。
・Oculus GoでスタンドアロンVR作業環境を作った
● Bluetooth Keyboard が使える
adb 経由で Settings 画面を呼び出せば Bluetooth 設定ができるようです。上の参考にさせていただいた Tips ページで直接 Bluetooth 画面を呼び出す方法が紹介されています。
下記のように設定画面の Top を呼び出すことも可能です。(追記 2019/02/06: この方法ではダイアログが操作できない場合があることがわかったので非推奨です。詳細はこちら)
adb shell am start -a android.intent.action.MAIN -n com.android.settings/.Settings
毎回 PC 上で呼び出すのも大変なので、単独で使えるよう設定画面を呼び出すアプリを作成しました。(後述)
● 一般のアプリが動く
通常の Android apk を Oculus Go にそのまま install しても VR に対応していないためライブラリに表示されません。ところが公式アプリの Oculus TV を起動すると、一部のアプリが下の方に表示されていました。選択すると VR 空間の TV の中で実行できるようです。
特に Termux は何もしなくても表示されており、apk install だけでそのまま使うことができました。↓

どうやら Oculus TV には Android TV に対応したアプリが表示されるようです。AndroidManifest.xml に LEANBACK_LAUNCER を登録しておけば Oculus Go の上で実行できることになります。
Linux 環境を走らせるアプリ UserLAnd には LEANBACK_LAUNCER が入っていないので Oculus TV から見えませんでした。ダミーアプリを作って Intent で呼び出せば Oculus TV の上で実行できそうです。
こちらで紹介されていた TvAppRepo というアプリがまさにそれで、Android TV 用のダミーアプリを実機上で作ることができます。
● UserLAnd を呼び出すだけのアプリを作る
実際にアプリを作ってみます。AndroidStudio で Android TV 向けの空 Project を作ります。Tempalte で Android TV Activity を選択しておき、Activity 起動直後に UserLAnd を呼び出します。
// MainActivity.java
import android.app.Activity;
import android.content.ActivityNotFoundException;
import android.os.Bundle;
import android.content.pm.PackageManager;
import android.content.Intent;
public class MainActivity extends Activity {
@Override
public void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.activity_main);
PackageManager manager= getPackageManager();
Intent it= manager.getLaunchIntentForPackage( "tech.ula" );
it.addCategory( Intent.CATEGORY_LAUNCHER );
startActivity( it );
}
}これだけでうまくいきました。apk 作ってを Oculus Go に install すると Oculus TV にアイコンが並びます。起動すると Oculus TV の上で UserLAnd が動きました。
Bluetooth Keyboard があれば任意の Linux Distribution を使うことができます。これでテキストエディタ、日本語入力、開発用言語など、様々なものが動きます。
この UserLAnd を呼び出すだけの簡単なアプリをこちらで公開してみました。ついでに Real VNC Viewer と設定画面も呼び出せるようにしています。
● VNC を起動する
LuserLAnd が内部で呼び出している bVNC Free は残念ながら Oculus Go で動きませんでした。VR を無視して全画面表示になってしまいます。代わりに Real VNC Viewer (com.realvnc.viewer.android) が動いたのでこちらを使います。UserLAnd と全く同じように Wrapper アプリで呼び出せるので TVWrapperUL に追加しました。
UserLAnd で動いている tightvncserver の port は 5951 です。VNC Server のアドレスには “127.0.0.1:5951” を指定してください。
● 手順の詳細
(1) Oculus Go を Develoepr mode にして PC と adb で接続します。
(2) TVWrapperUL の apk を Oculus Go に install してください。
adb install TVWrapperUL1.0.apk
(3) Oculus TV から TVWrapperUL を起動。Settings → Bluetooh で Bluetooth Keyboard をペアリングしておきます。
(4) UserLAnd (tech.ula) と RealVNC Viewer (com.realvnc.viewer.android) の APK を adb で Oculus Go に install します
(5) Oculus TV → TVWrapperUL → UserLAnd で起動します。
(6) 任意の Linux Distributon を選択します
Keyboard を使って Username, password, VNC password を入力。ここでは SSH を選びます
日本語化を行えば、そのまま Console で文章書き環境として利用可能です。
↓Ubuntu の Console で日本語入力
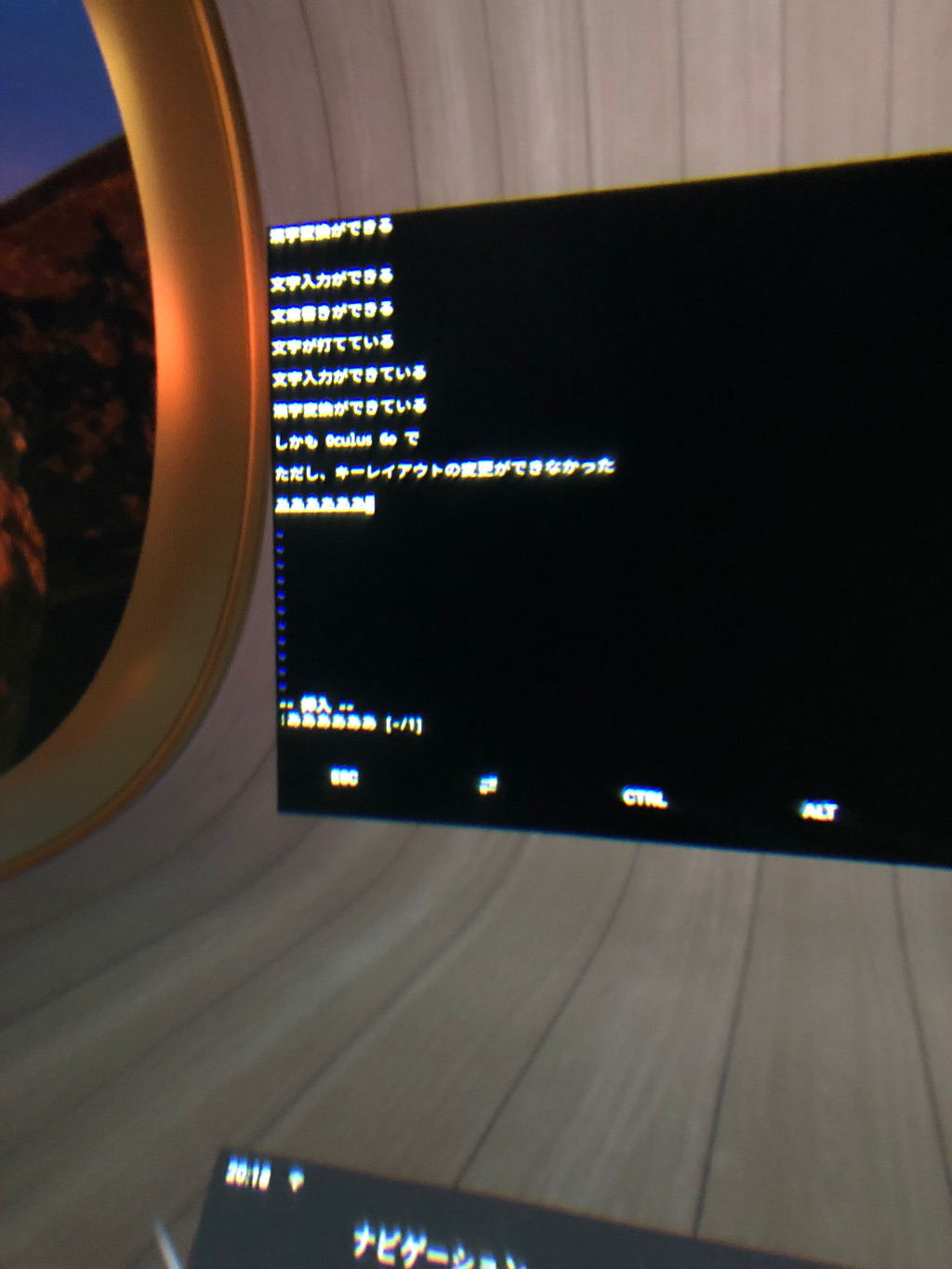
Desktop (lxde 等) 環境も VNC 経由で使うことができます。
● VNC 接続手順
(1) Oculus TV → TVWrapperUL → UserLAnd
(2) Linux Distributon を選択。User を作って VNC を選択
すでに SSH で作ってある場合は下記の手順で VNC 切り替えます。
1. 長押しして Stop App
2. もう一度長押しして App Info → VNC に切り替え
3. Distribution 名をクリックすると起動
(3) Client アプリがないと言われるので一旦 OK して、Controller のメニュー(←) ボタンを何度か押して戻る
(4) Oculus TV → TVWrapperUL → RealVNC を選択
(5) 右下の + ボタンを押して New Connection 画面から設定を追加。Address は “127.0.0.1:5951” 名前は任意
(6) (5) で作った設定を選んで CONNECT を押す。User 作成時に決めた VNC Password を入れると繋がります。
・Desktop の install 手順、VNC 解像度指定方法などはこちらを参照してください。
● 課題など
Android 設定画面から物理キーボードのレイアウト変更ができませんでした。設定画面が落ちるため。(追記: X11 desktop なら xmodmap による変更は可能) (追記 2019/02/06: Oculus TV + TVLauncherGo から設定を呼び出せばできることがわかりました)
Oculus Go Controller を使ったマウス操作が難しいかもしれません。
Oculus TV 上で起動したアプリは画面キャプチャが禁止されているらしく、画面を保存できなくなっています。ミラーリングも真っ黒な画面です。
(追記 2019/02/06: UserLAnd 以外も呼び出せるランチャーを作りました。詳細はこちら「Oculus Go で一般 Android アプリを起動できるランチャーを作ってみた」)
関連ページ
・Android の上の開発環境: UserLAnd
関連エントリ
・UserLAnd とブラウザ
・Android 上の開発環境と UserLAnd
・OS の中の Linux (WSL/Chrome OS/Android UserLAnd)
・ARM CPU 上の開発環境とコンパイル時間の比較 (2) Pixel 3/UserLAnd
・Gear VR のヘッドセットの種類のまとめ
・Oculus Go は VR ができる新しい携帯ゲーム機