近年の Intel CPU はスマートフォンや Apple と同じような非対称な CPU Core を採用しています。高性能コアと呼ばれる P-Core と、高効率(低消費電力)コアである E-Core の組み合わせです。この非対称な構造は Core i の第 12 世代 (Alder Lake) から用いられており、Core i9 で比較すると以下のようになります。
| CPU | P-Core | E-Core | 合計コア数 | 合計スレッド数 | ||
|---|---|---|---|---|---|---|
| 2021年 | Core i9-12900K | AlderLake | 8 | 8 | 16 | 24 |
| 2022年 | Core i9-13900K | RaptorLake | 8 | 16 | 24 | 32 |
| 2023年 | Core i9-14900K | RaptorLake Refresh | 8 | 16 | 24 | 32 |
P-Core はシングルスレッド性能が高く HT に対応しているものの消費電力が高く強力な冷却が必要になります。E-Core はピーク性能が低い代わりにコンパクトでより多くの Core を搭載できます。
Windows 10 が問題なのは、OS のスケジューラーがこの非対称な CPU コアの性能を引き出すことができずに著しく性能が落ちてしまう場合があるからです。
実際に Core i7-13700 を使用して Windwos 10 で UnrealEngine 5 のビルド時間を測定してみます。Core i7-13700 は Core i9-12900K 同様 8P + 8E の 16コア、24スレッドの CPU です。
| CPU | Core | Core数 | Thread数 | RAM | SSD | ビルド時間 | 比較 |
|---|---|---|---|---|---|---|---|
| Core i7-13700 | RaptorLake | 16 | 24 | 64GB | NVMe 4 | 80分32秒 | ↑遅い |
| Ryzen 5 3600 | Zen2 | 6 | 12 | 32GB | NVMe 3 | 77分46秒 | | |
| Core i7-11700K | RocketLake | 8 | 16 | 32GB | SATA | 68分46秒 | | |
| Ryzen 9 3950X | Zen2 | 16 | 32 | 64GB | NVMe 4 | 36分03秒 | ↓速い |
- VisualStudio 2019、 UE5 5.1.1 の Development Editor をビルドしたときの時間の比較
- ビルドにかかった時間が短い方が高速
ビルド時間で旧世代の CPU 「Core i7-11700K」に敵いません。Core i7-13700 は K 無し (65W) モデルということもありますが、同じ 65W でコア数が半分以下の CPU 「Ryzen 5 3600」にも負けていることがわかると思います。
Core i7-13700 のビルド速度が予想以上に遅くなっている原因はタスクマネージャーを見るとすぐに分かります。下はビルド中のタスクマネージャーをキャプチャしたものです。
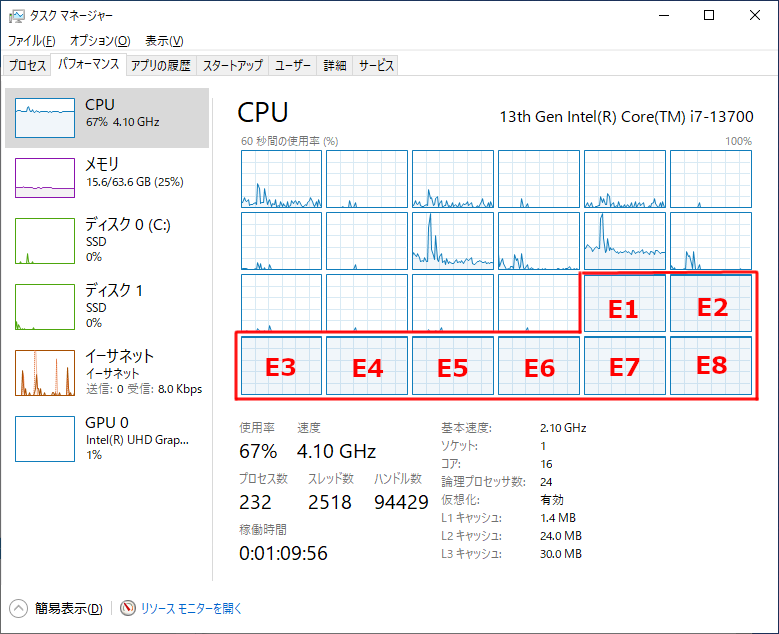
↑ 本来 24スレッドあるはずなのに 1/3 の 8スレッドしか稼働していません。しかもこの 8 スレッドはちょうど E-Core の 8個分に相当します。
UnrealBuildTool (UBT) は 8 コアにしか割り当てられていないことを知らないため、本来の 24 スレッドと認識しています。ビルド中は 14 個ものコンパイラが起動しており、これがすべて E-Core 8個に押し込められてしまうわけです。
そこで、UEFI (BIOS) で E-Core を無効化して P-Core だけを使ってビルドしてみることにします。以下の表にその結果を載せています。E-Core を無効化するだけで 55分まで短縮されました。ビルドが 25分も早く終わります。
| CPU | コア数 | スレッド数 | RAM | SSD | ビルド時間 | 比較 | |
|---|---|---|---|---|---|---|---|
| Core i7-13700 | 無変更 | 16 | 24 | 64GB | NVMe 4 | 80分32秒 | ↑遅い |
| Core i7-13700 | E-Core 無効化 | 8 | 16 | 64GB | NVMe 4 | 55分43秒 | ↓速い |
原因と回避方法など
ビルド中のタスクマネージャーを見ると、コンパイラは「基本優先度」が「通常以下」(BelowNormal) の状態で走っていることがわかります。
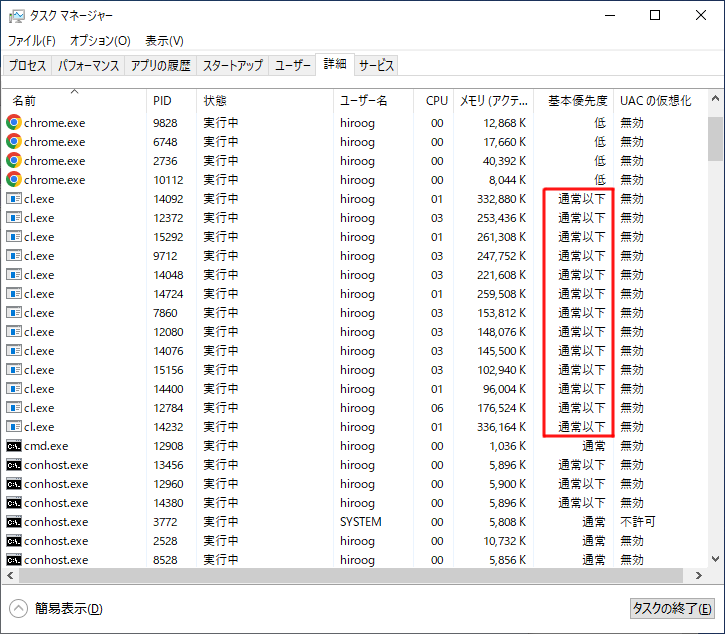
Windows 10 のスケジューラはおそらく、優先度が「通常」(Normal) より低い場合に E-Core に割り当てる仕組みになっているものと思われます。実際に UE5 5.1.1 の UnrealBuildTool の設定値を書き換えて、プロセスの優先度を Normal まで上げるときちんと全部の CPU Core にタスクが割り振られるようになりました。
UnrealBuildTool だけでなく、同じ問題は他のツールでも発生します。例えばシェーダーのコンパイル (ShaderCompileWorker) も同様で、負荷が E-Core のみに集中することがわかっています。
この問題は Windows 11 を使うことで解決します。
WIndows 11 では低プライオリティのタスクが E-Core だけに割り当てられてしまうことが無く、優先度が「通常以下」(BelowNormal) の場合でもすべてのコアを使用してビルドを行います。ビルド速度の比較表に Windows 11 での結果を加えてみました。
| CPU | コア数 | スレッド数 | RAM | SSD | ビルド時間 | 比較 | |
|---|---|---|---|---|---|---|---|
| Core i7-13700 | Windows 10 無変更 | 16 | 24 | 64GB | NVMe 4 | 80分32秒 | ↑遅い |
| Core i7-13700 | Windows 10 E-Core 無効化 | 8 | 16 | 64GB | NVMe 4 | 55分43秒 | | |
| Core i7-13700 | Windows 11 無変更 | 16 | 24 | 64GB | NVMe | 44分55秒 | ↓速い |
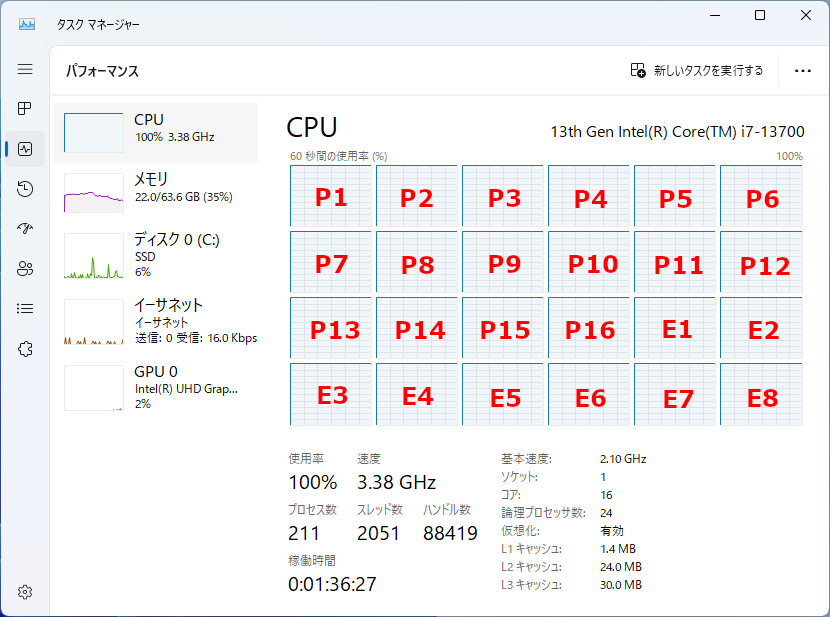
↑ Windows 11 にアップグレードするだけでビルド時間を 35分も短縮することができました。
タスクマネージャーでもきちんとすべてのコア、24スレッドが使われています。
なお、UE5 5.2 からは UnrealEngine 側でもこれらの対応が行われています。UnrealBuildTool (UBT) の ParallelExecutor 利用時は以下のように、CPU が非対称コアを搭載している場合、優先順位を「通常以下」(BelowNormal) ではなく「通常」(Normal) に設定するようになっています。
/// The priority to set for spawned processes.
/// Valid Settings: Idle, BelowNormal, Normal, AboveNormal, High
/// Default: BelowNormal or Normal for an Asymmetrical processor as BelowNormal can cause scheduling issues.
/// </summary>
[XmlConfigFile]
private static ProcessPriorityClass ProcessPriority = Utils.IsAsymmetricalProcessor() ? ProcessPriorityClass.Normal : ProcessPriorityClass.BelowNormal;そのため Windows 10 でも UE5 5.2 以降はエンジンのビルド時間が短縮されるようになりました。ただしこれは根本的な解決ではなく、ツール個別の対応になるため注意が必要です。もし対応していないツールが存在する場合 (他の UBT Executor や分散ビルドなど) はやはりパフォーマンスが低下してしまう可能性があります。
Core i 12000 シリーズ (第12世代, AlderLake) が出たばかりの頃はまだ Windows 10 搭載 PC も出荷されていました。せっかく新しい PC に入れ替えたのに、ビルド時間がかえって遅くなってしまうなんてことがありました。
流石に今はもう無いと思いますが、Alder Lake 以降の Intel CPU 上でゲーム開発を行う場合は Windows 11 を使用することをお勧めします。