AMD Z430 は PowerVR と同じようにタイルベースのレンダリング (TBR) を行うことで
知られています。TBR も Unified Shader の仕様も AMD は Xbox360 の GPU がベース
だと説明していますが、その両者の性能差は桁違いです。
一方は強力な GPU が要求するバス帯域に応えるため、もう一方はモバイル向けでタイトな
メモリ速度でもそれなりの性能を維持するため。同じ技術でも応用先の GPU が真逆なのは
面白いところです。
・AMD Next-Gen Tile-Based GPUs (pdf)
・AMD Next-Generation OpenGLR ES 2.0 Graphics Technology Achieves Industry Conformance
NetWalker に用いられている i.MX515 は GPU core として AMD (ATI) imageon Z430
を搭載しています。
ここ最近 NetWalker で OpenGL ES 2.0 を触っていますが、まだ Z430 の特性がうまく
つかめておらずあまり速度が出ていません。調べている最中です。
偶然 TBR のタイル領域の大きさを知ることが出来ました。
●タイルサイズ
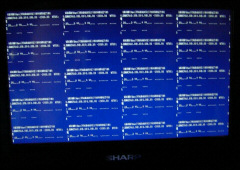
フレームバッファをクリアしないで描画した場合の画面がこれです。GPU のタイルバッファも
クリアせずに上書きされているようです。
1024×600 の画面なので、上の写真のケースだと 1タイルは 256×128 ドット。
以下バックバッファの組み合わせ毎にタイルサイズをまとめてみました。
Color Depth/Stencil Tile ----------------------------------- 16bit none 512x128 16bit 16bit 256x128 32bit 16bit 128x128 16bit 24bit/8bit 128x128 32bit 24bit/8bit 128x128
◎タイルバッファの容量
少なくても 128KByte 存在しています。予想より大容量です。
◎Depth/Stencil との組み合わせ
使用可能な depth の幅はカラーの影響を受けることが多いのですが、こちら で
書いたとおり Z430 では任意の組み合わせを選べます。PowerVR もそうだったので
やはり TBR 専用のバッファを持っているおかげだと思われます。
◎32bit Color or 24bit Depth 利用時の速度低下
Color か Depth どちらかを 16bit より増やすと速度に影響が出ます。
その原因はバス帯域だと思っていましたが、この結果を見るとタイル分割数の増加が
負担になっているのかもしれません。
● Extension
まだ試していませんが TBR を制御する API があります。
GL_VERSION: OpenGL ES 2.0
GL_RENDERER: AMD Z430
GL_VENDOR: Advanced Micro Devices, Inc.
GL_SHADING_LANGUAGE_VERSION: OpenGL ES GLSL ES 1.00
GL_EXTENSIONS:
GL_AMD_compressed_3DC_texture
GL_AMD_compressed_ATC_texture
GL_AMD_performance_monitor
GL_AMD_program_binary_Z400
GL_AMD_tiled_rendering
GL_EXT_texture_filter_anisotropic
GL_EXT_texture_type_2_10_10_10_REV
GL_EXT_bgra
GL_OES_compressed_ETC1_RGB8_texture
GL_OES_compressed_paletted_texture
GL_OES_depth_texture
GL_OES_depth24
GL_OES_EGL_image
GL_OES_EGL_image_external
GL_OES_element_index_uint
GL_OES_fbo_render_mipmap
GL_OES_fragment_precision_high
GL_OES_get_program_binary
GL_OES_packed_depth_stencil
GL_OES_rgb8_rgba8
GL_OES_standard_derivatives
GL_OES_texture_3D
GL_OES_texture_float
GL_OES_texture_half_float
GL_OES_texture_half_float_linear
GL_OES_texture_npot
GL_OES_vertex_half_float
GL_OES_vertex_type_10_10_10_2
GL_NV_fence
● NetWalker の速度比較
描画面積を出来るだけ小さくして頂点速度を測定しようとしたもの。
AMD Z430 48000x1 = 48000 Tris/s 30fps = 約 1.44M Tris/s (1024x600) PowerVR SGX 535 48000x4 = 192000 Tris/s 45fps = 約 8.64M Tris/s ( 480x320)
フレームバッファのサイズが極端に違うし、どちらも Unified Shader なので頂点に
ピクセルの影響が全くないとは言い切れません。Clear → Swap だけでもあまり速度が
出ないので、広い画面が仇になっている可能性があります。
タイル+転送だけである程度の負荷がかかり、頂点も圧迫しているのでしょうか。
1024×600 は 480×320 のちょうど 4倍の面積です。
1024x600 = 614400 pixels 8 倍 NetWalker 640x480 = 307200 pixels 4 倍 VGA 480x320 = 153600 pixels 2 倍 iPhone 320x240 = 76800 pixels 1 倍 QVGA
● VRAM 容量
PC のチップセット内蔵 GPU と同じように、VRAM はメインメモリから確保していると
考えられます。NetWalker の RAM は 512MB ですが 480MB しか見えないので、残りの
32MB が VRAM の取り分かもしれません。
1024×600 x16bit は 1.2MB (fb は 2.5MB) なので、32MB もあると少々無駄に感じる
かもしれません。ところが OpenGL ES 2.0 を使っていたらあっという間に VRAM が
溢れました。(GL_OUT_OF_MEMORY を返す)
その原因は自分のローダーでした。Z430 が DXT に対応していないため、圧縮された
テクスチャを 8888 に展開していたからです。あらかじめ ATC/3Dc/ETC へ変換して
おけば解決するはずです。計算したらテクスチャを 23MB も読み込んでいました。
もう一つ考えられる理由は TBR による遅延レンダリングです。
システムメモリからの逐次転送できず、シーンに必要なリソースを全部 VRAM に乗せて
おかないと描画できないのかもしれません。何らかの確証があるわけではなくあくまで
想像です。
どちらにせよ、設定を変えられるなら VRAM 容量はもうちょっと増やしたいところです。
●立ったまま OpenGL ES 2.0 プログラミング
帰りの電車の中では立ったまま、EGLConfig のパラメータを変えて make したりタイルの
データ取りをしてました。この大きさで開発+実行できるのは良いですね。
関連エントリ
・NetWalker PC-Z1 i.MX515 OpenGL ES 2.0 (3)
・NetWalker PC-Z1 i.MX515 OpenGL ES 2.0 (2)
・NetWalker PC-Z1 i.MX515 OpenGL ES 2.0
・OpenGL ES 2.0 Emulator
時間が無くて実は全く試せていません。
頂点が遅い結果となってますが、考えられる原因として頂点キャッシュが
無い可能性が高いそうです。
つまり indexed の triangle list ではなく、strip 化すれば理論上の
ポリゴン性能は 3倍になると言うこと。(頂点は増えない)
逆に pixel の方が余裕あって、あまり速くない代わりに多少の負荷なら
大丈夫そうとのことです。
内部のバスは余裕あるようです。この辺が TBR らしい感じです。
i.MX515 は結構何でも機能が付いていて高機能ですね。